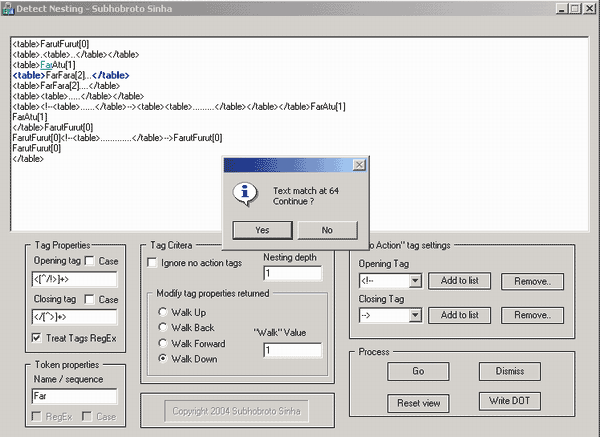
The match is colored in green and underlined. The matching tag pair is in blue bold style. Note that the tag pair does not enclose the tag, but it's highlighted because we have asked the app to show the tag pair which is one tag "down" the real matching tag.
Introduction
First of all, it's very much recommended that you go through the introductory part of this series - otherwise a few things may seem very foggy.
In this part, we will have a look at the implementation of the ideas we had developed in the first part of this series. Just explore it through some C++ code which drives the demo MFC GUI application.
However, just to keep you interested (and so that you may be able to use the implementation in your own applications, if you want to), we will not go into the guts of the code, as yet. But, I will just talk about the functionality exposed by the various classes of this software package.
So here goes.
The classes - using the code
So that you can start hacking at the code
ASAP, I will now discuss the role of the various classes which do the work behind the scenes.
At the heart of the engine is CTagList which is declared as :
class CTagList
{
structTagList* m_pTLNode;
structTagList* m_pTLStackHead;
structTagList* m_pTLFather;
CTagList* m_pctlFather;
void IWriteDOT();
public:
CTagList();
CTagList(TagInformation* ptiIn);
CTagList(TagInformation* ptiIn,
structTagList* pTLFather, CTagList* pctlFather);
virtual ~CTagList();
void Add(TagInformation* ptiIn);
structTagList* AddSubList(
TagInformation* ptiInsertInto, TagInformation* ptiIn);
bool Update(TagInformation* ptiIn);
void Remove(TagInformation* ptiIn);
structTagList* GetParent(structTagList* ptlSubList = NULL) const
{
structTagList* ptlParent = NULL;
GetParentList(ptlParent, ptlSubList);
return ptlParent;
}
const TagInformation* GetParent(DWORD dwStartingTagPos) const
{
if(dwStartingTagPos == 0xFFFFFFFF) return NULL;
structTagList* ptlTemp = GetParent(
GetListPtrFromStartingTagPosition(dwStartingTagPos));
return (ptlTemp?ptlTemp->m_ptiData:NULL);
}
const CTagList* GetParentList(structTagList* &ptlMatchingNode,
structTagList* ptlSubList = NULL) const;
structTagList* GetListPtrFromStartingTagPosition(
DWORD dwStartingTagPos) const;
structTagList* GetListPtrFromOffset(DWORD dwOffset) const;
const TagInformation* GetNestIDFromOffset(DWORD dwOffset) const;
structTagList* WalkUp(structTagList* pTLWrapTag,
DWORD& dwTagWalkUpNumber) const;
structTagList* WalkBack(structTagList* pTLWrapTag,
DWORD& dwTagWalkBackNumber, BOOL bWalkUpTree = FALSE) const;
structTagList* WalkBack(structTagList* pTLWrapTag) const {
DWORD dwTagWalkBackNumber = 0xFFFFFFFF;
return WalkBack(pTLWrapTag, dwTagWalkBackNumber);
}
structTagList* WalkBack() const { return NULL; }
structTagList* WalkForward(structTagList* pTLWrapTag,
DWORD& dwTagWalkFwdNumber, BOOL bWalkDownTree = FALSE) const;
structTagList* WalkDown(structTagList* pTLWrapTag,
DWORD& dwTagWalkDownNumber) const;
structTagList* GetStackHead() const { return m_pTLStackHead; }
structTagList* GetHeadNode() const { return m_pTLNode; }
bool Push(DWORD dwStartingTagPos, DWORD dwOpeningTagLen,
DWORD dwNestingDepth);
bool Pop(DWORD dwClosingTagPos, DWORD dwClosingTagLen);
void Display(SSlot& connectFunc);
void WriteDOT();
};
Now that was just the header listing. Now we will walk through the listing, and discuss what all those functions are doing in there :
structTagList is a structure which forms the node of each double linked list (Each double linked list holds information about tags of the same rank in the forest, i.e tags which potentially form siblings in the forest.) used to build the forest. |
CTagList(TagInformation* ptiIn, structTagList* pTLFather, CTagList* pctlFather) :
The most important parameterized constructor yet. The arguments serve the following purposes :
TagInformation* ptiIn : Pointer to the newed up TagInformation type which essentially holds information about the tag being added to the forest.
structTagList* pTLFather : Denotes the father of the tag(s) being added.
CTagList* pctlFather : Denotes the father of the tag(s) being added. (Hmm.. a CTagList can be downgraded to a structTagList. Maybe I need to look this over - it will remove the second argument to this constructor..)
void Add(TagInformation* ptiIn) : Adds/appends the TagInformation to the sibling list
Note that both the parameterized constructors call Add() internally.
structTagList* AddSubList(TagInformation* ptiInsertInto,TagInformation* ptiIn) :
Assigns a new CTagList object with ptiIn properties under an existing CTagList object with ptiInsertInto properties. Also, increments dwEnclosedTagNumber for the parent tag(s). It searches the current CTagList object's sublists (if any) if the tag info could not be matched for the current list's root.
Returns a structTagList* which should be the intended stack header indicating success, else NULL.
The specialty of this function is that it traverses each double linked list (tags which potentially form siblings in the forest) in the forest, until it finds out the correct tag under which the sublist should be created. And it allocates storage and creation of a new CTagList if the tag's the first child; otherwise, it simply appends the new node to the existing CTagList.
I mentioned this so that you would not have to worry about searching out the correct tag yourself, and then calling this function. It will be taken care of. |
In fact, it's this function which builds the forest.
const TagInformation* GetParent(DWORD dwStartingTagPos) const :
Returns the TagInformation part of the parent of the node which represents the tag starting at offset dwStartingTagPos.
const CTagList* GetParentList(structTagList* &ptlMatchingNode, structTagList* ptlSubList = NULL) const :
Returns the CTagList which is parent to the list ptlSubList. On successful completion, it fills ptlMatchingNode with the matching parent node.
If no match was found, a NULL is returned.
It must be noted that it's this function which allows us to follow the nodes up the forest, effectively climbing up the trees.
structTagList* GetListPtrFromStartingTagPosition(DWORD dwStartingTagPos) const :
Returns a structTagList* representing the tag at offset dwStartingTagPos.
structTagList* GetListPtrFromOffset(DWORD dwOffset) const :
Returns a structTagList* denoting the deepest tag set containing dwOffset.
What it actually does is search for the tag nearest to the offset dwOffset, and return the structTagList* of the matching tag.
const TagInformation* GetNestIDFromOffset(DWORD dwOffset) const :
Returns the const pointer to deepest/nearest TagInformation object which includes the item pointed at dwOffset.
Similar to the above function, except for the return type.
The
Walk* are special functions which highlights the power afforded by the engine. But before stating
what they do, I would like to start by stating
why the were written in the first place.
What's with all the Walking ?
You know ! Sitting all day long and coding does not do much for the buttocks - walking now and then helps !
But wait ! These functions do not ask you to take a walk now and then when you use them ! But they surely help in taking a load of your shoulders when text processing is concerned (so that you can put in the saved time in something else - probably take a walk ?).
Anyways, back to business.
What these functions do, is actually walk the forest in the way you want it to, by employing each specialized "walk" function.
"What do you mean ?" you say. Well, often it so happens that in structured documents (documents of type we are interested in processing) some sections remain invariant, while some sections change frequently.
Now, if the invariant section is the text we are interested in processing, we are safe. But if it so happens that the text we are interested in changes frequently, then we have to really sweat it out while using usual searching tools, as we have to aware what has changed and where the change has taken place.
As this is supposed to be a helpful engine, I could not have it suffering the same limitations as other processors. So I came up with the following idea :
| The invariant sections, though not directly related with our goal of text processing, can be employed to serve the purpose of reference positions in relative to which we can represent the variant sections (in which we are interested), thus easing processing, and reducing the amount of work you have to do significantly.
Thus, after identifying and locating the invariant sections, we can use the "walk" functions to seek out our interest easily. |
For example, consider the following two snippets :
<!--
(some more HTML and stuff here..)
Hello World.
(some more HTML and stuff here..)
<!--
<!--
(some more HTML and stuff here -
not necessarily identical to the previous one..)
Something on something or the other.
(some more HTML and stuff here - not necessarily
identical to the previous one..)
<!--
Now we are interested in operating on the message body ("Hello World" etc..). Note that they are invariant, but notice that there are two invariant sections in the document, namely
<!--
and
<!--
It's important to note that there might be any number of tags (not all of the same number of occurrence in both the text) between these sections and our message body. Thus even a regular expression lookup would be
extremely complex, leave alone composing one.
Taking any one of these tags, we can reach our required message text.
If we were to take
<!--
as a reference, we would typically use
WalkForward() or
WalkDown() as may be the case. (Typically, calling these functions would give us the target location from which we can do
anything with the text - write the message to a separate file, format it, spell check it, etc..)
Or we can even ask the function themselves to call each other as applicable ! Coming to that in a moment.
Obviously, as the illustration was simple, the solution looks a trifle redundant, but believe me, it's really useful for complex structures.
Now an overview of the "walking" functions :
structTagList* WalkUp(structTagList* pTLWrapTag,DWORD& dwTagWalkUpNumber) const :
"Walks up" the tree dwTagWalkBackNumber times (if possible), from pTLWrapTag.
The resulting value in dwTagWalkBackNumber (it's a reference) indicates the number of tags remaining to be "walked up".
If it's 0, then we have successfully walked up the requested number of nodes.
structTagList* WalkBack(structTagList* pTLWrapTag, DWORD& dwTagWalkBackNumber, BOOL bWalkUpTree = FALSE) const :
"Walks back" (retraces) dwTagWalkBackNumber number of tags/nodes in the "tree" which wraps the node pTLWrapTag.
If we get the m_ptlPrevious as NULL (implying the tag to be the first one in that list), then it means that we have to climb up the tree (except when pTLWrapTag is a root tag) and repeat the process until we have "gone back" the required number of tags.
We will only climb up the tree if bWalkUpTree is TRUE. Otherwise, if it's FALSE and we would have required to climb up the tree, we just return an empty object.
NOTE: If pTLWrapTag be a root tag, we check if m_ptlPrevious pointers exist.
If so, we go back dwTagWalkBackNumber nodes. Of course, the bWalkUpTree is redundant in this case as we cannot "walk up" a root node.
Thus, it's recommended to check the value of dwTagWalkBackNumber (it's a reference) after calling this function :
dwTagWalkBackNumber will contain the number of tags remaining to be walked back.
If dwTagWalkBackNumber is 0, then it indicates success, and has walked back the requested number of tags.
Else, if it's equal to the requested value, then there can be two conclusions based upon the structTagList* returned:
- If under this case, the
structTagList* returned is not NULL, then pTLWrapTag was a root tag, and there was NO other tag before it
- Else, if a
NULL was returned, there must have been an error, most probably due to a BUG in the code (provided pTLWrapTag was NOT a NULL itself !). |
structTagList* WalkForward(structTagList* pTLWrapTag, DWORD& dwTagWalkFwdNumber, BOOL bWalkDownTree = FALSE) const :
"Walks Forwards" dwTagWalkFwdNumber nodes from pTLWrapTag.
If all nodes at current depth from pTLWrapTag have been "walked", and dwTagWalkFwdNumber is not yet 0, then if bWalkDownTree is true, this will go down the tree, into the child nodes.
Returns a structTagList* matching the request.
The value of dwTagWalkFwdNumber after call indicates the number of tags remaining to be walked forward. This should be 0 if the request completed sucessfully.
structTagList* WalkDown(structTagList* pTLWrapTag, DWORD& dwTagWalkDownNumber) const :
"Walks down" the tree dwTagWalkDownNumber times (if possible), from pTLWrapTag.
Returns a structTagList* matching the request.
The value of dwTagWalkDownNumber after call indicates the number of tags remaining to be walked down. This should be 0 if the request completed successfully.
The important feature of these functions is that they will always return the match closest to the requested one (if such a tag exists).
As a result, you must always check the value of dwWalkType for 0 to ensure that the TagInformation that you are receiving is the requested one.
In the event that the "walk" could not be completed successfully, the value of dwWalkType will indicate the number of tags that remained be "walked" for a successful operation.
However, the respective function will return information about the tag matching the request closely (something's better than nothing).
This functionality gives the added advantage that you can pass a very large value to walk, and after calling function, you can gauge from the value of dwWalkType as of the closest match possible !
This allows you to make some assumptions about the document (without beign sure of it), and check if that assumption came true (or almost true for that matter..).
DetectNesting Demo - The engine in action
This article includes a MFC GUI application which you can play with to get the feeling of what I blabbered about for so long, all these pages. An example text file has also been packaged with the demo application so that you can understand what it does.
If you feel that I should write down the details in how to use it, please let me know. I think that the GUI is self-explanatory, so did not write anything on it. Note that not all functionality is implemented as of now though ! It's still incomplete !
To see how it works, as well as a few hands on step through through the code, see Part 3 of this series.
Want some more ? Click your way to Part 3
Did you like this article ? Want to know the guts of the system ?
This was just a superficial listing about the functionality of the engine.
Just don't wait !
In Part 3 of this series, you get to know about this engine, and the way it works, including in-depth discussion about some of the functions exposed, and why they are designed so in code !
It's in Part 3 that we get our hands dirty in some C++ code. See you there.
Credits
- Chris for his code to maintain the Combo width
- Joseph M. Newcomer for parts from
CIDCombo
- Kamal for designing the GUI and fixing a few traversal bugs
- .. others who I forgot to mention
History
- 2004-07-25 : First revision
He began programming since standard 8, about age of 14.
Looking back, being from a family of engineers, innocent inquisitiveness (and the destruction that comes along with it) came naturally to him (much to the dismay of others around who actually *owned* the property under inspection..).
Perhaps that only can explain why he plugged his father's HiFi's Line-In into the A.C Power socket in order to hear what 60Hz A.C. Might sound like. That research ended prematurely with fireworks originating from the amplifier, and needless to say, a very disturbed father.
That was at the age of 12. And there are reports - isolated incidents - of exploding Coke cans filled with hydrogen obtained from the electrolysis of salted water using a hand made full wave rectifier. Ah, and there are some other things better left unsaid..
Now that he has attained adulthood and realized the folly of his old ways, he just sits tight and writes code as long as he can keep his eyes open.









 News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin