
GUID Tree Data Structure
5.00/5 (4 votes)
Data structure designed to store billions of items using GUID as a key.
Introduction
With modern day data analysis, we come across a situation where we have billions of records, each with its own GUID. How do we organize terabytes of data and retrieve what we want?
The solution I describe uses GUIDs as a key, but a more generalized solution is possible.
Background
While working at my previous company, someone mentioned that they had billions of records to process. They wanted to count the number of unique GUIDs, but couldn't find a useful tool to use. The idea popped into my head and here's the result.
The solution is based on the notion of a base n key with m digits. In the case of a GUID, we have 32 hexadecimal digits. As a result, we can create a tree structure with a depth of 32 (for each of the digits in the GUID). Each node would have an array of 16 sub-trees attached to it.
A simplified example is seen below:
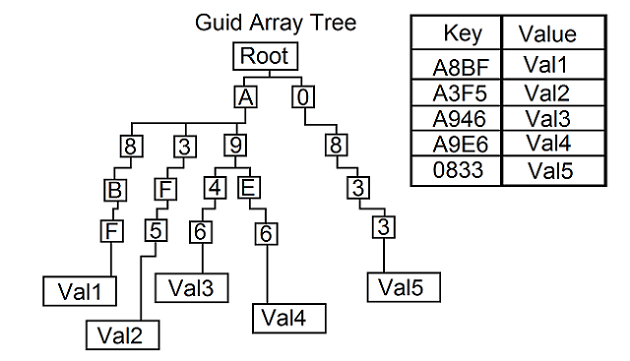
Under A, below the root, the array contains 3 elements, with links to 3 sub-trees. The
System.Guid method ToByteArray() returns a byte array of 16 bytes. Since a byte contains 256 possible values, that seemed like an unnecessary use of memory. As a result I split it into a 32 element byte array, where each element contained a hexadecimal value. This allows for a node with an array containing 16 sub-trees, instead of 256 sub-trees. I could have used a linked list instead of an array, but I didn't want to increase retrieval time. I sacrificed memory for performance. The solution presented uses two types of data structures, depending on the number of records you need to store.
Memory Based
For small data sets, when we are certain all data can be stored in memory. The above data structure is used here.
File Based
For large data sets consisting of billions of records. The solution uses the file system to store data. The above data structure is represented as a series of file system directories. The limitation is that you need a drive with sufficient memory. You will need to use a spanned hard drive to store all the billions of records you need to work with. This is currently single-threaded, although a multi-threaded solution is possible.
Using the code
For the in-memory solution:
// Create collection for memory-based storage
GuidCollection<int> guidCollection = new GuidCollection<int>();
// Key we will use
Guid newGuid = Guid.NewGuid();
// Add
guidCollection.Add(newGuid, 5);
// Contains key
bool res = guidCollection.ContainsKey(newGuid);
// Count
int count = guidCollection.guidArrayTree.Count;
// Allow overwriting data
guidCollection.OverwriteValues = true;
// Index (set)
guidCollection[newGuid] = 10;
// Index (get)
int val = guidCollection[newGuid];
// Enumerate
foreach (int intVal in guidCollection.GetEnumerator())
{
System.Console.WriteLine("Value is: " + intVal);
}
// Retrieve
int retrivedValue;
guidCollection.TryGetValue(newGuid, out retrivedValue);
// Remove
guidCollection.Remove(newGuid);
For the file-based solution:
// directory where we store the data structure
string dir = "C://TestDir/";
// Create collection for file-based storage
GuidCollection<int> guidCollection = new GuidCollection<int>(dir);
// Key we will use
Guid newGuid = Guid.NewGuid();
// Add
guidCollection.Add(newGuid, 5);
// Contains key
bool res = guidCollection.ContainsKey(newGuid);
// Count
int count = guidCollection.guidArrayTree.Count;
// Allow overwriting data
guidCollection.OverwriteValues = true;
// Index (set)
guidCollection[newGuid] = 10;
// Index (get)
int val = guidCollection[newGuid];
// Enumerate
foreach (int intVal in guidCollection.GetEnumerator())
{
System.Console.WriteLine("Value is: " + intVal);
}
// Retrieve
int retrivedValue;
guidCollection.TryGetValue(newGuid, out retrivedValue);
// Remove
guidCollection.Remove(newGuid);
Points of Interest
The GetEnumerator() method required recursion, since we are dealing with a deeply embedded data structure and each level had multiple entries.
I got stuck on that, until I found this
article: http://stackoverflow.com/questions/2055927/ienumerable-and-recursion-using-yield-return
Adding and retrieving data is in linear time. However, we pay for this in terms of memory usage.