
Generating Facebook Like Preview using Regular Expression
4.83/5 (7 votes)
Download page as HTML string. Parse it using regex and extract desired contents to generate Facebook Like Preview.
Introduction
This article will show you, how to generate Facebook like link preview when user inserts any url?
Background
To understand this, Knowledge of Webrequest, and regular expression is necessary.
Using the code
First of all, we need to understand What is WebRequest?
WebRequest is request/response model to access the data over the internet. Request sent from client to the server. Based on request server will return the response to the client. WebRequest throws webexception if any error in accessing the resources over the internet.
for more information refer [https://msdn.microsoft.com/en-us/library/system.net.webrequest(v=vs.110).aspx].
What is Regular Expression?
Regular expression is formed of special characters and alpha-numeric characters which describes search pattern for particular scenario.
for example
if we need to check that any enter value is valid amount format or not.
We know that valid amount format is any number following by two decimal places. i.e. 99.99
for that below regular expression can be useful.[It's just an example, not accurate regex]
([0-9]{7}\.[0-9]{2})

image credit : https://regexper.com/ (licence - no modification)
Now, We have basic understanding of WebRequest and Regex (Regular Expression).
If we remember, what facebook does when we paste any link in status block? It creates a preview, which consist of image/s, Title of the website, valid url and Description.
Sometimes we won't get any description or image/s. So, question is Why it doesn't display any image, sometimes?
To understand this we need to understand that What scenario may be used by the Facebook. As per my study, I came to know that, It uses meta tags of the website to fetch the details which are necessary to generate the preview. If any website won't have any meta tags which includes image,description then they'll be not shown in the preview.
We are going to use the same scenario. But, Here we are giving user a functionality to enter any Url without HTTP and/or HTTPS.
In first step, we'll take user's input. When user enters any Url, first of all we need to format the url to make a WebRequest.
suppose user had enters "google.com". so, we'll have four url's from which we'll get WebResponse from atleast one Url from the list of Urls.
possible list of Urls
1) http://google.com
2) https://google.com
3) http://www.google.com
4) https://www.google.com
How to make a WebRequest? and How to check its Response? please refer below code.
// making a webrequest
HttpWebRequest request = HttpWebRequest.Create(Url) as HttpWebRequest;
// webresponse
response = request.GetResponse() as HttpWebResponse;
if (response.StatusCode.ToString().ToLower() == "ok")
{
//valid url
}
Once we get a valid Url, We need to Download the rendered HTML page as a string on which we can apply regex and exctract the information we needed to generate the preview.
To download the rendered HTML page as string, refer below code.Taken from [ http://www.mikesdotnetting.com/article/49/how-to-read-a-remote-web-page-with-asp-net-2-0 ]
public static string GetHtmlPage(string strURL)
{
string strResult;
HttpWebRequest objRequest = (HttpWebRequest)WebRequest.Create(strURL);
objRequest.UserAgent = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.121 Safari/535.2";
WebResponse objResponse = objRequest.GetResponse();
using (var sr = new StreamReader(objResponse.GetResponseStream()))
{
strResult = sr.ReadToEnd();
sr.Close();
}
return strResult;
}
once we have downloaded the Html page as a string, we need to exctract the information which we required.
First of all, We'll exctract the meta tags. To exctract the meta tags we need to build a regex which helps to exctract all the meta tags in the page.
regex : <meta[\\s]+[^>]*?content[\\s]?=[\\s\"\']+(.*?)[\"\']+.*?>

image credit : https://regexper.com/ (licence - no modification)
How do we exctract the meta tags using above regex? refer below code. match-collection logic from [ http://www.dotnetperls.com/scraping-html ]
public static MatchCollection GetWebPageMetaData(string s)
{
Regex m3 = new Regex("<meta[\\s]+[^>]*?content[\\s]?=[\\s\"\']+(.*?)[\"\']+.*?>");
MatchCollection mc = m3.Matches(s);
return mc;
}
once we have exctracted the metatags, we need to exctract og:image, og:description and og:title from it. refer below code
var metadata = GetWebPageMetaData(s);
if (metadata != null)
{
foreach (Match item in metadata)
{
for (int i = 0; i <= item.Groups.Count; i++)
{
if (item.Groups[i].Value.ToString().ToLower().Contains("description"))
{
scrap.desc = item.Groups[i + 1].Value;
break;
}
if (item.Groups[i].Value.ToString().ToLower().Contains("og:title"))
{
scrap.title = item.Groups[i + 1].Value;
break;
}
if (item.Groups[i].Value.ToString().ToLower().Contains("og:image"))
{
if (string.IsNullOrEmpty(scrap.image))
{
scrap.image = item.Groups[i + 1].Value;
}
break;
}
else if (item.Groups[i].Value.ToString().ToLower().Contains("image") && item.Groups[i].Value.ToString().ToLower().Contains("itemprop"))
{
scrap.image = item.Groups[i + 1].Value;
if (scrap.image.Length < 5)
{
scrap.image = null;
}
break;
}
}
}
}
If we got all the required contents, then we're done here. We've valid url, image, site description and site title. Simply return the contents to the view.
What if we didn't get any description?
if we haven't get any description, we're not looking for it in the page because we haven't find it in metatag. we can take anyline or paragraph from the body tag, but we're skipping it as who knows that the very first paragraph of the site is of the same site? it can be of any advertisement!!
What if we didn't get any image?
In this case, we'll parse the html string using regex to get all the img tags withing the Html page. After parsing [passing], we'll look for image which contains "logo" as naming. 80 to 90 % chances are of getting logo of the site. 10 to 20% chances that we'll get the logo but that can't be of the same site.
Refer below code to exctract images. taken from [ http://stackoverflow.com/questions/20184532/c-sharp-regex-img-src ]
public static List<string> GetRegImages(string str)
{
List<string> newimg = new List<string>();
const string pattern = @"<img\b[^\<\>]+?\bsrc\s*=\s*[""'](?<L>.+?)[""'][^\<\>]*?\>";
foreach (Match match in Regex.Matches(str, pattern, RegexOptions.IgnoreCase))
{
var imageLink = match.Groups["L"].Value;
newimg.Add(imageLink);
}
return newimg;
}
Now we have list of all the images on the page. It is possible that we get the image url in the following manner.
/images/someimage.jpg
Well, if we have image url of as above, we can't render the image on our page as it is located in the inner folder of some site. To access it we need to have it's full image path i.e. http://SomeSiteUrl/images/someimage.jpg
We'll format the images urls as we did to find out a valid site url previously. After formating images url, we'll check for a valid working image url by creating a WebRequest.
We'll repeat this step until we got the four images in our list.
What if we didn't get og:title from metatags?
In this case we'll look for the title tag using regex.
We're done here. We've got the all required contents to make facebook like preview. Return the contents to the page. Apply Valid CSS to get exact view like facebook's link preview.
Steps to implement
1) open visual studio and create new project.

2) select Asp.net web application and give the project name FacebookLikePreview

03) select MVC template, and click on change authentication

04) check no authentication and click on ok

05) Go to solution explorer, right click on models and click on New Folder and Name it VM (View Model)

06) right click on VM and Add a class file. Name it Scrap.cs


07) now goto home controller and implement the logic. Here, I've not shown the all code snippets as it'll increase the length of the article.

08) Create two view models as shown in the below image.
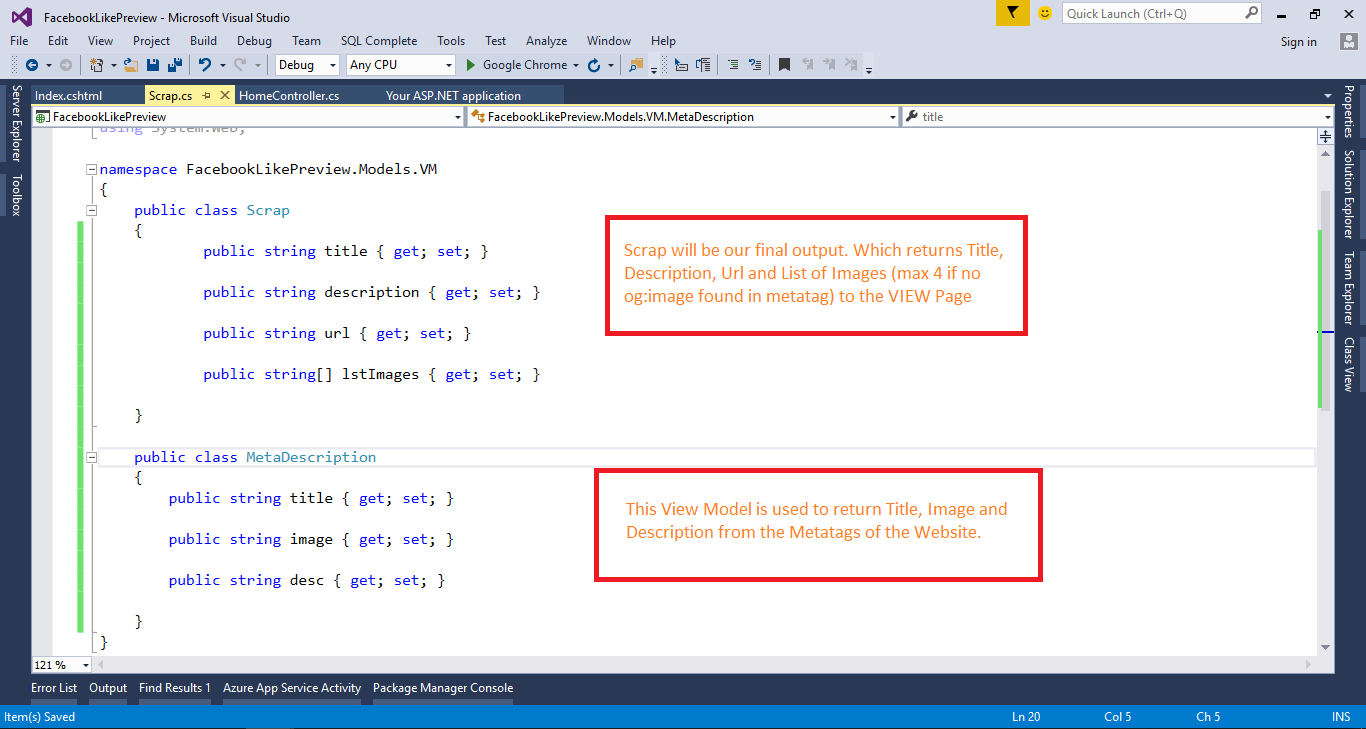
09) go to index.cshtml page and create view. When user enters any url and hit the Generate preview button then an Ajax call will made to the controller which will return required things. All required things will be bind using jquery.

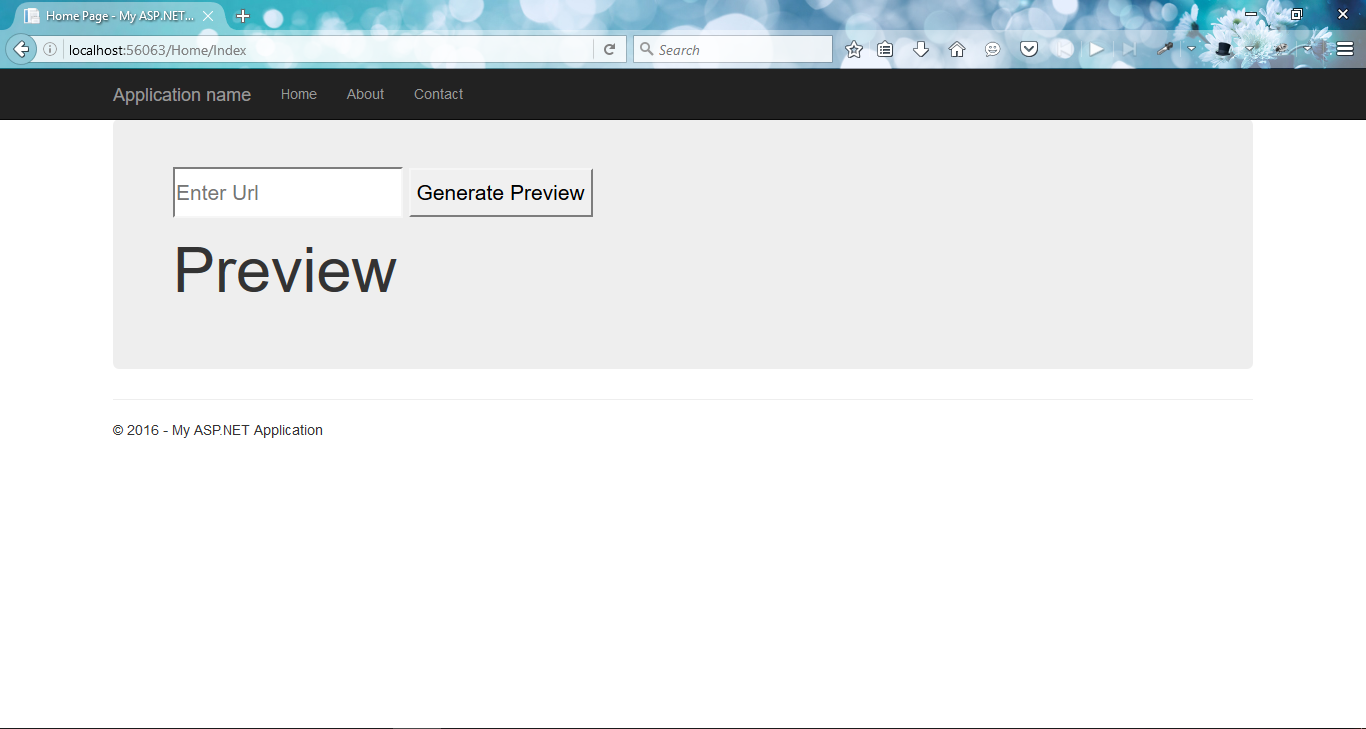



Note: Initially I tried to achieve this concept using HtmlAgility pack. But later on go for regex as it is accurate to parse the html page to get desired output.
Reference
1) https://code.msdn.microsoft.com/Exctract-from-web-address-c9895a2f
3) http://mantascode.com/c-programmatically-download-all-images-from-a-website-and-save-them-locally/
5) http://www.codeproject.com/Articles/1041115/Webscraping-with-Csharp
6) http://stackoverflow.com/questions/6887910/regex-for-extracting-image-file-links