
Data Modeling with Indexes in RavenDB
In this article, we’ll be covering how you can leverage RavenDB indexes to do much more than help create high-performance queries.
Introduction
RavenDB is a cross-platform high-performance NoSQL document database. In this article, we’ll be covering how you can leverage RavenDB indexes to do much more than help create high-performance queries.
In traditional relational databases, indexes serve to optimize how the database reads data to make queries perform better. For example, if you have a “products” table and you wanted to perform a query “get product by name” you would probably add an index onto the “name” column so the database understands to create a lookup. This makes it faster for the database to find your products by name as it doesn’t need to perform a full table-scan lookup and can instead leverage the index.
When it comes to data modeling, indexes in relational databases usually don’t enter the equation. However, in RavenDB, indexes serve not only to enhance query performance but also to perform complex aggregations using map/reduce transformations and computations over sets of data. In other words, indexes can transform data and output documents. This means they can and should be taken into account when doing data modeling for RavenDB.
How do indexes work in Raven?
Index definitions are stored within your codebase and are then deployed to the database server. This allows your index definitions to be source-controlled and live side by side with your application code. It also means indexes are tied to the version of the app that is leveraging them making upgrades and maintenance easier.
Indexes can be defined in C#/LINQ or JavaScript. For this article, we’ll use JavaScript to show off this feature of RavenDB. It’s worth noting that JavaScript support for indexes supports up to ECMAScript 5 but this will increase as the JavaScript runtime RavenDB uses adds support for ES2015 syntax in the near future.
Calculating Order Totals
To understand basic indexes, let’s first take a look at a simple example of defining an index to query product orders for an e-commerce site.
In the database, you might have an “Order” document:

Let’s make a new index to allow querying by customer and to calculate the order total. Indexes can be defined using map and reduce functions--the whole index definition is larger but throughout the article we’ll just focus on the core map/reduce functions.

map("Orders", order => {
return {
Customer: order.Customer
}
})
This index is a “map” index which takes documents and transforms them into an output index result. This index selects the Customer property on an Orders collection.
This would allow us to issue a query to find all orders for a specific customer:

from index 'Orders' as o
where o.Customer == 'Customers/101-A'
This is using RavenDB Query Language (RQL) and resembles LINQ from .NET or SQL but uses JavaScript expressions within the query. In this case, we are querying the map index we’ve created to find orders by a specific customer ID.
Let’s now add a calculated property representing the order total from the Order.LineItems:

map("Orders", order => {
return {
Customer: order.Customer,
Total: order.LineItems.reduce(
(sum, x) => x.Quantity * x.Price + sum, 0)
}
})
Now we’ve added a new “Total” calculated field to the index. As you can see, we are leveraging standard JavaScript support for the reduce array function to sum the order line items.
Calculating the order total during indexing time allows RavenDB to quickly respond to queries without performing the order total computation in real-time. This computational power can be extended even further to perform more complex aggregations.
Calculating Yearly Totals
So far we’ve seen an example of a simple map index with a computed field. RavenDB also supports map/reduce indexes, which provide the ability to perform aggregate operations across mapped index documents.
Perhaps for example we’d like to know the total revenue across all our orders for the year and furthermore we’d like to know what the average order total is.
First, in the map function we will need to include some new fields to aggregate on including the order year stored in the OrderedAt document property:

map("Orders", order => {
return {
Year: new Date(order.OrderedAt).getFullYear()
Customer: order.Customer,
AverageTotal: 0,
OrderCount: 1,
Total: order.LineItems.reduce(
(sum, x) => x.Quantity * x.Price + sum, 0)
}
})
If you’ll notice, we need to add AverageTotal and OrderCount to the map function since in RavenDB both the map-reduce functions output result have to match. By setting OrderCount to 1 during the map phase, it acts as a counter that we can use to find the average during the reduce phase.
Now we will add a reduce transformation that happens after the map:

groupBy(order => order.Year)
.aggregate(group => {
var year = group.key;
var count = group.values.reduce((sum, x) => x.OrderCount + sum, 0);
var total = group.values.reduce((sum, x) => x.Total + sum, 0)
return {
Year: year,
Total: total,
OrderCount: count,
AverageTotal: total / count
}
})
This is a bit more interesting! First we group by year since we need a key to aggregate on. Then we sum the order count and total to get the yearly aggregation. Finally, we use both those calculations to fill in the AverageTotal.
Remember from earlier that RavenDB allows you to deploy your indexes from code. While executing JavaScript in your database might sound like it harkens back to relational-style stored procedures, this code still lives in your own codebase subject to the same build, review, and deploy process your application code is subject to. Furthermore, RavenDB has the ability to reference external scripts that will be made available scoped to the index definition during execution.
Predicting the Future
Using map-reduce indexes to aggregate data across documents is a powerful feature but the previous example hinted as to what’s really possible with RavenDB indexes using date computation.
Instead of limiting ourselves to calculating historical totals and averages, would it be possible for an index to use the data it’s aggregating to predict future data that we can query on?
Let’s switch gears from managing orders to managing customer subscriptions. In this example, we are providing a subscription service that customers can pay monthly or yearly. We’d love to know future projected income for the next 3 months using the past 3 months historical data to easily query and display in some business reports or even on the website in real-time.
The Customer documents we are storing contain all previous payments made by that customer since their inception which we’ll use to aggregate and predict the future.

{
"Name": "Sam Samson",
"Status": "Active",
"Subscription": "Monthly",
"Payments": [
{ "Date": "2019-01-01", "Amount": 58 },
{ "Date": "2019-02-01", "Amount": 48 },
{ "Date": "2019-03-01", "Amount": 75 },
{ "Date": "2019-04-01", "Amount": 42 },
{ "Date": "2019-05-01", "Amount": 34 }
]
}
In our future revenue index, we will need to map the customer payments into a result that we can use to aggregate against. Our goal is to “predict” 3 future payments based on the customer’s subscription type (monthly or yearly), the average of the previous 3 months, and return those in any queries on the index.

map("Customers", cust => {
// Reverse the array
var latestPayments = cust.Payments.reverse();
// Determine last payment date and components
var lastPayment = latestPayments[0];
var lastPaymentDate = dayjs(lastPayment.Date);
// Average of up to last 3 payments
var recentPayments = latestPayments.slice(0, 3);
var recentAmount = recentPayments.reduce(
(sum, x) => x.Amount + sum, 0);
// Generate next 3 payments based on subscription type
var futurePayments = [1, 2, 3].map(i => {
var nextPayment = cust.Subscription === "Monthly"
? lastPaymentDate.add(i, 'month')
: lastPaymentDate.add(i, 'year');
return {
Date: nextPayment.toDate(),
Amount: recentAmount / recentPayments.length
}
});
return cust.Payments.concat(futurePayments).map(payment => {
return {
Date: new Date(payment.Date),
Amount: payment.Amount
}
})}
)
Using JavaScript with RavenDB allows you to “add additional sources” and in this case we are taking advantage of the tiny Day.js date helper library to make date manipulation easier. This includes the module in a global scope that we can reference in the indexing functions.
This map function is much more involved than previous examples but its premise is still straightforward:
- Starting from the last recorded payment date, create 3 new payment entries for future dates
- Depending on the type of subscription, take the previous 3 periods of payments and average them to use as the predicted payment for the next 3 periods
- Concatenate the extra payments onto the customer payments
- Map a new index result with the payment date and amount
Index results are not immutable and can be transformed like this to slice and dice data as you see fit. In this case, we essentially generate 3 new payment records to append to the payments of the customer. These are not saved on the Customer document but they will be available in the index results and any queries against the index.
You may notice that we are generating N+3 payment results per Customer document--this is referred to as a “fan-out” index in RavenDB and it does require some careful consideration since an unbounded resultset could cause performance degradation.
So far this index will tell us what the projected payments are for individual customers but now we can add a reduction phase to the index to give us a much better picture of all expected payments for the next 3 months.

groupBy(payment => payment.Date)
.aggregate(group => {
return {
Date: group.key,
Amount: group.values.reduce((sum, x) => x.Amount + sum, 0)
}
})
The reduce phase is much smaller. We use the payment date as the key and through that we calculate the expected total payments for every month included in the map phase. This will tell us what we want to know: current payments with a 3-month forecast.
This would be an expensive operation to perform in real-time using traditional querying methods but with Raven’s background indexing, queries against this index are lightning fast and can be used to create real-time reports.

Building a shopping cart using event sourcing
So far we’ve seen examples of RavenDB indexes able to perform map transformations along with more complex aggregation across each map result. The final example will kick it up a notch as we see how we can construct an entirely new domain model from sequences of events also known as event sourcing.
First let’s explain conceptually how event sourcing would work in a familiar setting: a shopping cart. When a user adds items to a cart, removes items from a cart, and checks out, these operations could be considered mutating the state of a “shopping cart” entity. However, storing a user’s cart as a single entity can become complex due to various interactions between systems like address checking, validation, supply chain, and accounts payable. Do you pass the entire cart around as an object across service boundaries? In microservice architectures this would be a massive pain.
Instead, a pattern like event sourcing can help you to think differently about a cart, not as a single object but as a state in time. Rather than thinking each user action mutates some domain entity once, consider the actions themselves. When a user adds an item to the cart, you can record an “AddToCart” event. If they remove an item, “RemoveFromCart” and when they finally pay, a “PayForCart” event. When you replay these events for a user’s session, building up the state one event at a time, at the end you will have a representation of the user’s cart. These events could still trigger other events in downstream systems without having to share a complex shopping cart context. This has many added benefits such as providing an audit history of a cart, reconstructing a cart from scratch given only an event stream, reporting on price changes to added items, and allowing multiple consumers of events.
This is the example we’ll walk through next using RavenDB indexes. Events like AddToCart, RemoveFromCart and PayForCart will be represented as individual documents tied to a user, as shown below:





{
"Product": "products/12-A",
"Cart": "carts/294-A",
"Quantity": 1,
"Price": 17.4,
"@metadata": {
"@collection": "AddItemToCart"
}
}
{
"Product": "products/12-A",
"Cart": "carts/294-A",
"Quantity": 1,
"Price": 17.4,
"@metadata": {
"@collection": "AddItemToCart"
}
}
{
"Product": "products/21-A",
"Cart": "carts/294-A",
"Quantity": 1,
"@metadata": {
"@collection": "RemoveItemFromCart"
}
}
{
"Cart": "carts/294-A",
"Paid": 0.5,
"Method": "Cash",
"@metadata": {
"@collection": "PayForCart"
}
}
{
"Cart": "carts/294-A",
"Paid": 20,
"Method": "Visa",
"@metadata": {
"@collection": "PayForCart"
}
}
There are some products added to the cart, a quantity is adjusted, and then some payments occur for the cart. This is an event stream that we can use to build the state of the cart.
The final output cart model we desire from the index should look like this:

{
"Cart": "carts/294-A",
"Products": {
"products/12-A": {
"Quantity": 1,
"Price": 17.4
},
"products/21-A": {
"Quantity": 1,
"Price": 3.1
}
},
"Paid": {
"Cash": 0.5,
"Visa": 20
},
"TotalPaid": 20.5,
"TotalDue": 20.5,
"Status": "Paid"
}
To compose these individual documents into this final shopping cart model, we’ll start by mapping the shape of the shopping cart we expect as an output. Remember, each map/reduce transformation in the index must have the same output shape, so we’ll initialize an “empty” shopping cart model in the map with the flattened event data.
First, we will process the “AddToCart” events:

map("AddItemToCart", event => {
var products = {};
products[event.Product] = {
Quantity: event.Quantity,
Price: event.Price
};
return {
Cart: event.Cart,
Products: products
};
});
This map function has much more logic going on here. We are storing the products we are adding using a dictionary to make it easy to perform efficient O(1) lookups. RavenDB has a configurable safeguard on the number of statements an index step can evaluate, so we need to take care and ensure our logic is efficient.
It may seem like we are overwriting the product dictionary for duplicate products but this is the map phase, so each event document will output a single result in the shape above.
The next step is to merge these disparate dictionaries into one by using the Cart as the group key. This is where we will take care of incrementing the quantity or reusing existing product dictionary entries.

groupBy(x => x.Cart)
.aggregate(g => {
var products = g.values.reduce((agg, item) => {
for (var key in item.Products) {
var p = item.Products[key];
var existing = agg[key];
if (!existing) {
agg[key] = { Quantity: p.Quantity, Price: p.Price };
}
else {
existing.Quantity += p.Quantity;
existing.Price = Math.min(p.Price, existing.Price);
}
}
return agg;
}, {});
return {
Cart: g.key,
Products: products
};
})
In the reduce step, we build up a new “agg” aggregate object to return by iterating through each map result object. If the product key doesn’t exist in the aggregate, we store the map result directly. If it does exist, we need to do two things: a) increase the quantity and b) choose the lowest price amount. Choosing the lowest price is effectively a business rule and we decided that if a customer adds the same product multiple times before checking out, we only want to reflect the lowest price.
We now have both a map and a reduce operation in the index--but we’ve only handled one type of event. We need to handle the “RemoveFromCart” and “PayForCart” events. RavenDB allows indexes to have multiple map operations (a “multi-map” index) which is what we’ll now take advantage of.
The additional map operation to map “RemoveFromCart” can now be added:

map("RemoveItemFromCart", event => {
var products = {};
products[event.Product] = {
Quantity: -event.Quantity,
Price: 0
};
return {
Cart: event.Cart,
Products: products
};
});
But this changes our reduce logic. We need to ensure we delete a product from the cart dictionary if its quantity reaches 0; remember this is an event stream so the operations could happen in any order. Since we are also using Math.min for finding the lowest price and a “RemoveFromCart” event sets the price to zero, we need to ignore updating the price in that case.
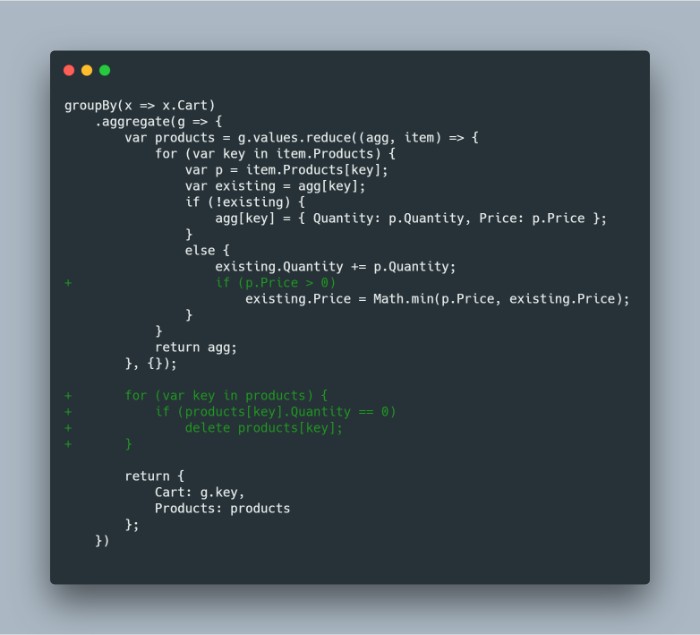
groupBy(x => x.Cart)
.aggregate(g => {
var products = g.values.reduce((agg, item) => {
for (var key in item.Products) {
var p = item.Products[key];
var existing = agg[key];
if (!existing) {
agg[key] = { Quantity: p.Quantity, Price: p.Price };
}
else {
existing.Quantity += p.Quantity;
if (p.Price > 0)
existing.Price = Math.min(p.Price, existing.Price);
}
}
return agg;
}, {});
for (var key in products) {
if (products[key].Quantity == 0)
delete products[key];
}
return {
Cart: g.key,
Products: products
};
})
Finally, we need to handle the “PayForCart” event, we’ll create another map function to handle it:

map("PayForCart", event => {
var paid = {};
paid[event.Method] = event.Paid;
return {
Cart: event.Cart,
Products: {},
Paid: paid
}
});
Note the new “Paid” property added to the result object. That also means we need to update the other map functions to include an empty Paid dictionary (again, so all the output shapes match).
In the reduce function, we’ll now include aggregate payment information for the cart:

groupBy(x => x.Cart)
.aggregate(g => {
var products = g.values.reduce((agg, item) => {
for (var key in item.Products) {
var p = item.Products[key];
var existing = agg[key];
if (!existing) {
agg[key] = { Quantity: p.Quantity, Price: p.Price };
}
else {
existing.Quantity += p.Quantity;
if(p.Price > 0)
existing.Price = Math.min(p.Price, existing.Price);
}
}
return agg;
}, {});
for (var key in products) {
if(products[key].Quantity == 0)
delete products[key];
}
var paid = g.values.reduce((agg, item) => {
for (var key in item.Paid){
agg[key] = item.Paid[key] + (agg[key] || 0);
}
return agg;
}, {});
return {
Cart: g.key,
Products: products,
Paid: paid
};
})
We are storing the dictionary of payment methods and amounts now on the aggregate object.
The last step is to include the final shopping cart properties we’d like to calculate: TotalPaid, TotalDue, and Status (whether or not the customer fully paid for the items).

groupBy(x => x.Cart)
.aggregate(g => {
var products = g.values.reduce((agg, item) => {
for (var key in item.Products) {
var p = item.Products[key];
var existing = agg[key];
if (!existing) {
agg[key] = { Quantity: p.Quantity, Price: p.Price };
}
else {
existing.Quantity += p.Quantity;
if(p.Price > 0)
existing.Price = Math.min(p.Price, existing.Price);
}
}
return agg;
}, {});
var totalDue = 0
for (var key in products) {
if(products[key].Quantity == 0)
delete products[key];
else
totalDue += products[key].Quantity * products[key].Price;
}
var paid = g.values.reduce((agg, item) => {
for (var key in item.Paid){
agg[key] = item.Paid[key] + (agg[key] || 0);
}
return agg;
}, {});
var totalPaid = 0;
for (var key in paid) {
totalPaid += paid[key];
}
return {
Cart: g.key,
Products: products,
Paid: paid,
TotalPaid: totalPaid,
TotalDue: totalDue,
Status: totalPaid === totalDue ? "Paid" : "Pending"
};
})
The new fields are calculated using the aggregate data and included in the output.
That’s it! What did all this buy us?
- The key concept is that by modeling events as documents an index can incrementally build a data model from a stream of events using a combination of map and reduce operations.
- Since index operations like map/reduce can be parallelized and run in the background this approach can scale handle cases from dozens to tens of thousands of events.
- The shopping cart model output has to match the shape across both map/reduce operations and while this may look strange at first, it’s a powerful technique
We can now query the index to filter and select the shopping cart, like so:


But wait, there’s more!

Storing index reduce results as documents
RavenDB allows you to save index results as physical documents in a kind of artificial collection. Each time the index runs, the results are then stored as documents, just like any you’d create from your application. That means we can not only use indexes to generate new domain entities we can then turnaround and create other indexes using those same stored documents.
We’ll start by checking the option to store index reduce results as a collection:

The new document will look exactly like the output shown in the previous section.

The ID of the document is the hash of the reduce key (the cart ID, in this case) so the same index cart result will get saved to the same document. RavenDB also marks the document as artificial coming from an index in the document’s metadata.
Since we can operate on these documents just like any other, we’ll create a new Sales By Product index that returns the sales by product, aggregated across carts:

// Map
map("ShoppingCarts", cart => {
var results = [];
if (cart.Status !== "Paid") {
return results;
}
return Object.keys(cart.Products).map(product => {
var sale = cart.Products[product]
return {
Product: product,
Amount: sale.Quantity * sale.Price
}
});
});
// Reduce
groupBy(x => x.Product)
.aggregate(g => {
return {
Product: g.key,
Amount: g.values.reduce((sum, p) => p.Amount + sum, 0)
}
});
This index runs through each cart document (generated by the other index above) and totals up the amounts by product, allowing us to query sales data without any extra events.
Essentially this allows you to build documents dynamically sourced from events and then read that aggregated data as domain entities from your application. This pattern works well for a single database but it also can enable highly-distributed scenarios. For example, designing an architecture using a write-only event database and replicating to a read-only query/reporting RavenDB instance or relational database using Raven’s ETL capabilities to replicate documents. This would allow you to leverage Raven’s advanced indexing capabilities for writes and then output to a read-only database for reporting/querying for applications.
Handling time-sensitive events
In an event sourcing scenario, or any indexing scenario that requires time-based logic, a common issue is handling the “order” of events. Since RavenDB is a distributed database, there is no guaranteed order in which documents are processed during indexing. However, in many scenarios, handling time-based events just requires rewiring your brain to think in terms of how RavenDB handles indexing--and you may find the actual order of documents doesn’t matter.
A familiar set of time-based events would be paying down a mortgage. In this scenario, the time a payment is applied is very important. Since we can’t rely on the order in which a document is processed, we’ll need to handle the situation a little differently.
A mortgage is complex and has many different stages but the two that we’ll concern ourselves with are:
- Approval - the mortgage has been created with an APR, term, and principal amount
- Withdrawal - when money is taken out, which may happen in installments
Since the payment of a mortgage has different terms and many factors like balloon payments, late fees or principal-only payments, we will calculate the amount due on a monthly basis for the next month’s expected payment. The mortgage creation and expected payment will be two types of events in the system, as well as a third event for the actual payment applied.
To start, we’ll have a “MortgageCreated” event:

{
"APR": 4.85,
"Address": {
"City": "Seattle",
"Country": "United States",
"Line1": "One Mortgage Way",
"State": "WA"
},
"DurationMonths": 216,
"Property": "properties/293994-C",
"TotalAmount": 364000,
"Mortgage": "mortgages/4993-B",
"@metadata": {
"@collection": "MortgageCreated"
}
}
This includes details for the term, APR, and principal amount for the mortgage.
Once we calculate an expected payment, it’s structure looks like:

{
"Amount": 444.77,
"DueBy": "2018-02-28T00:00:00Z",
"Interest": 258.67,
"Principal": 186.11,
"Mortgage": "mortgages/4993-B",
"@metadata": {
"@collection": "PaymentExpected"
}
}
And then an applied payment event will look like:

{
"Amount": 229.66,
"DueBy": "2018-02-05T00:00:00Z",
"Mortgage": "mortgages/4993-B",
"@metadata": {
"@collection": "MortgagePayment"
}
}
These are simplified examples but they showcase the situation of handling time-based events.
If we are a few months into the mortgage, this is what the expected payments might look like:

And then the actual payments applied by the customer:

Let’s define the map/reduce index to aggregate the payments by month. This will follow our previous example, creating a map operation for each event and then a final reduce operation, all of which have the same result shape:

map("PaymentExpected", event => {
return {
Mortgage: event.Mortgage,
DueBy: event.DueBy.substring(0, 7),
InterestDue: event.Interest,
PrincipalDue: event.Principal
}
});
map("MortgagePayment", event => {
return {
Mortgage: event.Mortgage,
AmountPaid: event.Amount,
DueBy: event.DueBy.substring(0, 7)
}
});
function normalize(r) {
return parseFloat(r.toFixed(3));
}
function sum(g, fetch) {
var r = g.values.filter(x => fetch(x) != null)
.reduce((acc, val) => acc + fetch(val, 2), 0);
return normalize(r);
}
groupBy(x => ({ Mortgage: x.Mortgage, DueBy: x.DueBy }))
.aggregate(g => {
var interest = sum(g, x => x.InterestDue);
var principal = sum(g, x => x.PrincipalDue);
var amountPaid = sum(g, x => x.AmountPaid);
var interestRemaining = 0, principalRemaining = 0;
if (amountPaid < interest) {
interestRemaining = normalize(interest - amountPaid);
principalRemaining = normalize(principal);
}
else {
principalRemaining = normalize(principal - (amountPaid - interest));
}
return {
Mortgage: g.key.Mortgage,
DueBy: g.key.DueBy,
PrincipalDue: principal,
InterestDue: interest,
PrincipalRemaining: principalRemaining,
InterestRemaining: interestRemaining,
AmountPaid: amountPaid
}
});
This time there is real business logic in the index--the fact that underpayments get applied to interest first and then principal. This is not something you’d actually put into your index logic but might represent instead with an “AppliesTo” property.
If we query this index, we’ll get the month-by-month aggregation:

There’s a problem with the customer’s payments--in March, the required payment increased but the customer underpaid for April. They still owe $1049.86.
This is a month-by-month view but if we wanted to get a global view of the mortgage we can use the same feature we showcased earlier by saving these index results as documents and then creating an index to calculate the status.
We’ll tell RavenDB to output reduce result documents to a collection “MortgageMonthlyStatuses”.

We’ll make a new index to take each status and the mortgage payments to determine the total amount paid on each mortgage:

map("MortgageMonthlyStatuses", status => {
return {
Mortgage: status.Mortgage,
PrincipalRemaining: status.PrincipalRemaining,
InterestRemaining: status.InterestRemaining,
AmountPaid: status.AmountPaid,
PastDue: (status.PrincipalRemaining + status.InterestRemaining) > 0 ? 1 : 0
};
});
map("MortgagePayment", amount => {
return {
AmountPaid: amount.AmountPaid,
Mortgage: amount.Mortgage
};
});
function normalize(r) {
return parseFloat(r.toFixed(3));
}
function sum(g, fetch) {
var r = g.values.filter(x => fetch(x) != null)
.reduce((acc, val) => acc + fetch(val, 2), 0);
return normalize(r);
}
groupBy(x => x.Mortgage)
.aggregate(g => {
return {
Mortgage: g.key,
PastDue: Math.max(0, sum(g, x => x.PastDue) - 1),
Amount: sum(g, x => x.Amount),
PrincipalRemaining: sum(g, x => x.PrincipalRemaining),
InterestRemaining: sum(g, x => x.InterestRemaining)
};
});
This index produces these query results:

The query results show that the mortgage is one month past due which means the remaining principal and interest reflect the missed month’s amount ($1049.86) and next month’s payment ($1494.64).
We can create the missing month’s payment event to close the missing amount:

{
"Amount": 1049.86,
"DueBy": "2018-04-30T00:00:00Z",
"Mortgage": "mortgages/4993-B",
"@metadata": {
"@collection": "MortgagePayment"
}
}
Once this event is processed, the index will update the total remaining to reflect the next month’s required payment amount.
This showcased an example of handling time-sensitive events without any dependency on the order in which documents were created or processed. It is not meant to be a comprehensive example of the complexities of mortgages but it does illustrate how using RavenDB indexes provides a powerful and compelling way to model those scenarios.
Conclusion
Unlike traditional databases, indexes in RavenDB are not only used to provide high-performance querying capabilities to your application but can transform and aggregate data in the background. Indexes can be used for simple map/reduce operations or to model complex scenarios and offload aggregation of data from your business layer to the data layer. There are even ways to use indexes to create a fully event-sourced system where documents are aggregated and then stored as artificial documents, enabling higher-order indexes to serve a read-only aggregation layer.
The example database containing all the indexes and documents above can be found here. Just import the dump into your own RavenDB instance! If you’re interested in learning more about RavenDB, you can find more information on the Learn RavenDB site.
