Table of Content:
- Introduction
- Program that cannot scale
- Tests and results
- A bit of theory
- Solution 1: Per-thread memory management
- UNIX-thinking vs. Windows-thinking
- Solution 2: Spawning processes
- Conclusion
- Appendix A: What's next?
- Appendix B: Attached files
- Appendix C: References
Introduction
What do you expect when running your application on a dual-processor computer? That it will run 2 times faster than on a single-processor computer? 1.5 times faster? And what if it runs slower?
With this article, I wanted to open a discussion on writing scalable server applications for SMMP computers (SMMP states for Shared Memory MultiProcessor). There is not much information I managed to find on the subject, so here I would like to share my experience and invite you to compel and discuss. Actually this concrete article discusses only one of many problems that a developer could face when programming for multiprocessor computers. My experience is not enough to fully cover the subject. I just believe you will find the story interesting.
Program that cannot scale
What does it mean that a program can scale?.. It means that the program takes advantage of all resources the hardware (and money) can provide. If there are 2 CPUs, the program will do the same work faster. If there are two separate computers, two instances of the program can be run to utilize both of them and do the work faster.
It happened that one of our project's background services is implemented around a 3rd party COM object DLL. This COM object performs a kind of statistical analysis, usually consuming up to 100% CPU and huge amounts of memory. Since it is a black box, its performance is a constant for us (to be honest, I must tell here that the performance of the component itself is quite good).
When working with multiple threads on single-processor servers, our background service performed very predictable. 2 or 3 parallel worker threads took slightly larger time to process X documents than one worker thread. And time of a single document processing increased linearly with amount of worker threads, so there is no point in having more than one worker thread per CPU.
It was natural to expect that a modern dual-processor server would improve the performance if not twice but at least 1.7 times. To our surprise, it appeared to be that 2 parallel worker threads run about 1.5 times slower than one worker thread! It run even slower than the same parallel worker threads running on a single-processor computer! The second CPU somehow made it slower. The service was not able to scale.
First we thought about a possible synchronization issue in the 3rd party component. But according to its developers. it has very little internal synchronization between object instances and it should not be the problem. And even if there is a problem, there is no way to fix it or replace the component. I was forced to search for other possible reasons.
After reading some books and sources on Internet, I started to wonder if the problem might come from the run-time library memory manager. A multithreaded application must use a multithreaded memory manager which allocates and frees blocks of memory for all threads from the same memory pool. If an application creates several in-process COM objects implemented in a DLL, each COM object will compete for the same memory manager.
Because of it, parallel threads in a memory intensive application must wait to each other until the memory manager is released. This is not a big problem on a single-processor system, because anyway only one thread can execute at one moment. But this becomes a problem on a shared memory multiprocessor system because of the memory manager which will stall all other CPUs while executing on one of them. Even on a single-processor computer it might be a problem, if we take into account the new hyper-threading feature of Intel Pentium 4 CPU.
Okay, it could explain why the application does not improve from having multiple processors. But why its performance degrades? I'll continue discovering it in the section 4. Now let's look at the hard numbers.
Tests and results
In order to confirm that there IS a problem with the run-time memory manager, I wrote a simple test application that is supplied with the article.
There are 4 types of tests I thought about:
- Pure computational test.
This test is a mix of mathematical functions that should scale very efficiently on multiple CPUs. It does not implement any real algorithm. I only wanted this test to fit into the cache and do not access the main memory.
- Pure memory allocation/destruction test.
If the guess is correct, this test should poorly scale on multiple CPUs. To simulate numerous allocations, I simply took the STL std::list<char> container that allocates a long linked list of chars. Since it is not a sequential container, it will allocate and then free each single character one by one - exactly what I need. Note that there is nothing wrong with STL! Any linked list that uses the run-time library memory manager will behave exactly the same.
- Mix of memory allocation/destruction and read/write.
This test may scale and may not scale - it depends on a balance between two parts. Its implementation is almost the same as test 2, I just added iterating through the container and doing some computations. During that loop, the memory manager should be free for other threads. I did not pay much attention to balancing this test.
- Pure memory read/write test.
This test should scale almost the same as the pure computational test. It may be just a bit less efficient because of the memory bus concurrency.
Each single test iteration was designed to take about 4-6 seconds on the test computers: a single-processor Pentium III 850 MHz with 256 Mb RAM and a dual-processor Pentium 4 2.4 GHz with 2 Gb RAM (it actually took 4-6 seconds on Pentium III and about two times less on Pentium 4). Any test data is generated on fly and it fits into RAM, so HDD cannot affect the results. By the way, I noted that my Pentium III 850 was only about two times slower than Pentium 4 2.4 when running a single thread. I guess it is because of the different priorities for foreground tasks that you can configure in Windows 2000 for desktop and server computers.
I executed 24 iterations with different counts of parallel worker threads and repeated the entire set of tests 3 times to see the distribution of the results. There were 1, 2, 3, 4 and 6 parallel threads:
- one thread processing 24 test iterations (1 x 24 = 24);
- two parallel threads processing 12 test iterations each (2 x 12 = 24);
- three parallel threads processing 8 test iterations each (3 x 8 = 24);
- four parallel threads processing 6 test iterations each (4 x 6 = 24);
- six parallel threads processing 4 test iterations each (6 x 4 = 24).
Total time of a single test execution was about (5 sec * 24 "documents" * 5 combinations * 4 tests * 3 iterations) = 2 hours and more on Pentium III.
On a single-processor computer, the results are very predictable. The tests 1 and 4 take almost the same time no matter how many parallel threads work together. They may loose a bit on context switching, but I could not even notice it. Just note that at the same time, parallel threads increase the time of each single test iteration processing linearly. Both the tests with memory allocation start loosing performance quadratically. It happens because of the CPU cache that cannot contain all data required by parallel worker threads. The more memory is accessed by the parallel threads, the less efficient caching becomes. Note that the test 4 is unaffected by this problem because all parallel threads access the same memory blocks, thus fully utilizing the CPU cache.
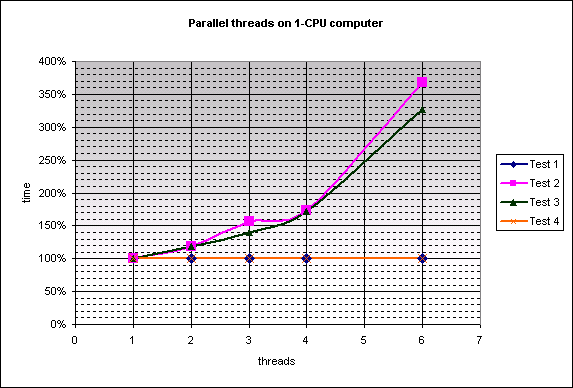
I normalized the results to percentages instead of giving milliseconds because it significantly simplifies the analysis. I also chose, from each three sets of results, one that looked most appropriate. You can find the original results attached together with the source code.
On a dual-processor computer the results are much more interesting! The pure computational test gets 200% of performance boost with two threads and 300% with four threads. Here I have to tell that this computer has hyper-threading feature enabled, so Windows 2000 even thinks there are four processors and displays four CPU windows in Task Manager. The memory access test performs a bit less efficient exactly as it was predicted (there are two processors and two caches that compete for one memory bus).
At the same time, the pure memory allocation test starts significantly degrading in performance once there is more than one thread executing in parallel. Four parallel threads process the same amount of documents in twice more time! Do not confuse it with four parallel threads on a single-processor computer - here we have two physical or four virtual processors (taking into account hyper-threading). It should not surprise that 6 parallel threads optimize the picture - having more than 2 threads per physical CPU allows more efficient caching of the memory manager's data structures (it may look like I contradict to myself, but for 2 caches, the cache coherence has much more serious performance impact than a single cache inefficiency). The mixed test first gains in performance for two parallel threads but then repeats the pattern of the pure memory allocation test.

Now let's try to discover why the test application performance degrades so significantly on a multiprocessor system. First, it is necessary to explain the most basic features of multiprocessing on Intel x86 architecture and Microsoft Windows operating system.
A bit of theory
Starting from NT 4.0, Microsoft Windows is a SMP operating system (SMP states for Symmetric Multi Processor). Simply speaking, it means that its kernel is able to process interrupts on any CPU available. (Windows 3.51 implemented asymmetric multiprocessing and was able to process interrupts only on CPU 0, which is less effective since this CPU becomes a bottleneck under specific workloads). It also means that all threads with the same priority are distributed evenly between available processors. When allocating CPU time for a thread, operating system prefers the CPU where the thread executed for the last time, thus making caching more efficient (this effect is called CPU affinity). If at any single moment, there is only one active thread executing on a multiprocessor computer, having multiple processors will not make any difference - the second processor will not be used. Usually only server computers that process numerous parallel requests feel the difference.
Intel processors family implements Shared-Memory Multiprocessor architecture (abbreviated as SMMP). This means that while each CPU has its own L1 cache, L2 caches and internal bus, all CPUs work with the main memory using one shared memory bus. In practice, it requires any change in the internal cache of one processor to be written back to the main memory right away if only any other processor tries to use this memory. This is done very efficiently using cache coherence protocol called MESI in Intel's terminology (look for a very good explanation of cache coherence in Windows 2000 Performance Guide, section 5.2). Unfortunately, anyway, two or more threads that actively read and write from/to the same memory location cause the affected CPUs to frequently flush their caches' content back to the main memory, stalling their execution pipeline. It does not happen on a single processor since it has no reason to write the cache content to the main memory until it needs the cache space for other tasks.
Theoretically, Windows 2000 working on a dual-processor computer without hyper-threading can work up to 1.7 times faster than an identical single-processor computer (look at Windows 2000 Performance Guide, section 5.2). A four-processor system could work about 3 times faster (very similar to our results in the pure computational test). Instead, in our example with the pure memory allocation test, excessive data dependency between parallel worker threads makes the cache coherence seriously impacting the application performance. Fun thing is that this data dependency is not imposed by incorrect algorithms or sharing our program data structures. We are perfectly clean in terms of our programming language (C++) - we use only the basic services like new/delete operators and each thread operates with its own independent data. It is the run-time library which shares its internal data structures between parallel execution threads.
Most of the run-time library routines do not use shared data structures, except the memory allocation routines. Run-time memory manager allocates large blocks of virtual memory from the operating system and supplies all threads with requested memory blocks. It is much more efficient than satisfying memory allocation requests using the operating system memory allocation facility. C++ language is unaware of parallel threads and each pointer must be freely accessible from any line of code. Therefore the run-time library memory allocation routines use the shared internal data structures to manage allocated memory blocks. There is the multithreaded version of C++ run-time library that synchronizes access to these internal data structures in order to protect a multithreaded application from corrupting them. The problem is not only in the synchronization but also in the fact that all threads allocate memory using the same internal data structures. When the application intensively allocates and frees memory blocks, these data structures become the real bottleneck on a multiprocessor system.
Of course, it does not mean that multiprocessor computers are inefficient. It does not mean also that the programming language is inefficient (may be only the way we use it). It does mean that a solution that works perfectly on a single processor system may not improve and even degrade in performance when moving it to a multiprocessor system.
The solution to enable scaling of our application is to isolate parallel execution threads one from another. More precisely, it is to isolate as much as possible standard memory allocations from parallel execution threads. This will minimize the spin locks and cache coherence issues and enable effective usage of all available CPUs.
Solution #1: Per-object memory management
The most obvious and most effective solution would be having a custom memory manager for internal needs of each object instance. Note that I'm still speaking about my concrete example, where each object is created to perform complex statistical computations. Using a custom memory manager, it would be possible to allocate all the memory required for its computations much more efficiently. It would be also possible to pre-allocate the memory, reuse it as needed, and free it all at once upon completion. And it would not need any synchronization.
There are numerous custom memory allocation schemes developed for concrete applications. You can simply use HeapCreate function to create a dynamic heap for each thread and/or object. Windows XP/2003 introduces a new low-fragmentation dynamic heap built on top of HeapCreate. You may find interesting the corresponding article from "Modern C++ Design: Generic Programming and Design Patterns Applied" by Andrei Alexandrescu. Or you might like a set of memory allocator classes from ACE framework. There are several articles on the subject here on CodeProject as well.
In my specific case, this solution is not relevant, because the problematic component is a 3rd party DLL. I started to search in a different direction.
UNIX-thinking vs. Windows-thinking
For a long long time, UNIX community lived without any thread support. Spawning a process in UNIX is a fast and efficient process, so any background task can be executed as a separate process. It is well supported by UNIX philosophy of fine-grained autonomous command-line utilities which can be combined using pipelining. A separate process runs in a separate address space thus protecting other processes from crashing, in case of any failure. A disadvantage of spawning is that any data exchange between processes requires some more or less complex inter-process communication protocol (IPC protocol).
Windows, almost from the beginning, supported threads. Threading has an advantage of more efficient data exchange because all threads within the same application have access to the same memory. But this also can become a disadvantage as in our case - a need for coordinating multiple thread activities complicates design and may negatively affect performance and stability.
Nevertheless, when properly used (as any other technology), threading is a very powerful feature. Many of UNIX flavors now support threading (for instance, in Linux it is quite a recent addition). A properly designed multithreaded server application in most cases will be more efficient than a similar multiprocess application (because of no need for any IPC protocols).
On the other hand, spawned processes are better isolated one from another and do not need synchronization of internal RTL functions. This feature, actually, gave me an idea of how to work around the problem. If each parallel processing task would run in a separate process and create only one instance of COM object, even the multithreaded run-time library that implements synchronization of its basic functions will run very efficiently since there is no concurrent access. Each process will attach a "separate instance" of the same DLL, so they will not interfere.
Solution #2: Spawning processes
Implementation of this solution was pretty simple. The only thing I needed was a suitable IPC protocol for managing multiple processing tasks. Also, I needed to solve a problem with expensive process creation - creating a new process for each processed document would ruin the performance of the entire system (there may be hundreds of input documents per second). There was an additional complication imposed by the client application - it is written in Java and uses JNI (Java Native Calls) interface which requires a stateless reentrant DLL (not exactly true because I can call back to the Java object properties and even change them, but then I need to map pointers to some Java data types and I was not sure it is a safe way).
What I knew for sure was that the input and output information is compact (about 1 Kb) and there are only few processing tasks that will execute in parallel (anyway it is not efficient to have more than 2-3 parallel running processes per 1 CPU). Each processing may take from tens of milliseconds to even minutes, depending on the input information, and in most of cases it varies from 0.1 to 10 seconds.
I decided to exchange input and output data using a shared memory table implemented in the JNI DLL that Java requires anyway. This DLL declares a shared memory table, creates new processes if necessary, passes input parameters and gets the results. Access to the shared memory table is synchronized by named mutexes and events. The processing tasks also load this DLL and register themselves. The system is self regulated - if a processing task crashes, the DLL will create a new one; if a processing task does not get input requests for specific timeout time, it will terminate automatically. The shared memory table has indeed one limitation - it is a bottleneck by itself :-). I decided that it is not significant under the system requirements I have: a four-processor server is able to run up to 8 parallel processing tasks (assuming hyper-threading). Managing 8 entries in the shared memory table would not impact performance noticeably.
But before running into design and implementation, I needed to prove that this solution will enable scalability of the component. In order to check it, I ran the same test application in parallel processes instead of parallel threads. Look at the diagram, they speak by themselves. The memory allocation test scales perfectly now.
A couple of important notes should be put there. Note that the best effect is seen when there are four parallel threads/processes because of the hyper-threading feature that makes two processors working like four. Another important thing is that while we gain 200% speed boost with four parallel processes, the time of each single "document" processing increases twice. This makes having six parallel threads/processes inefficient - while the total time processing time changes insignificantly, the single "document" processing time increases.
I also executed a similar test with parallel processes on a single processor computer. I executed only the test 2 so I do not provide the diagram here. It is just important to note that multiple processes behave exactly like the pure computational test in the first test - the graphic is a line parallel to the X-axis. The results of this test are also attached together with source code.
In real life, this solution did work for the background service I developed. By working around a 3rd party component that we could not change, we got an average 1.5-2.0 speed improvement. More important, this solution allowed scaling the component and the service.
Conclusion
As a result of this small research, I would summarize the following:
- The standard multithreaded C++ run-time library memory manager may have serious impact on application performance on multiprocessor servers. This impact is easy to miss during the application design stage because it is hidden in the run-time library design.
- It is especially important for applications that allocate complex data structures and are supposed to run in parallel threads (OOP techniques often encourage intensive memory allocation).
- In most of the cases, the problem can be avoided by using a custom memory manager. When it is impossible or difficult to replace the C++ run-time memory manager, there is a way to work around the problem by parallelizing the job to parallel processes instead of threads.
- Intel processors seem advancing to multikernel architecture (starting with hyper-threading in Pentium 4). Sooner or later, desktop applications will experience the same scalability problems as server applications.
I will appreciate your feedback on the article. Did I miss something obvious? Am I mistaken? Are there any other options?
Appendix A: What's next?
There are some Win32 API basic services that can significantly impact application performance when applying them to multiprocessor computers. For example, once we found a scalability problem with some component we used, and the company who developed it confirmed that there is a scalability problem because of overusing of GlobalAlloc() function. They plan to fix it in future releases. There may be other, not so trivial, problems and solutions. It would be nice to see more information and articles covering scalability issues.
Appendix B: Attached files
The attached archive contains the source code and a compiled executable of the test application. The test application is a console command line utility. Its source code is located in the sources sub-folder. The test application is developed on Visual C++ 6.0 SP 5 and you should not experience big problems moving it to newer versions of Visual Studio. For debugging of this test application, I used an improved set of debug macros (QAFDebug.h/cpp) described in my article Code that debugs itself.
There are several batch files developed for Windows 2000/XP command shell.
- run_threads.bat executes the complete test (3 sets) with parallel threads. This batch file does not require parameters and it calls to run_threads_impl.bat to do the work. This test produces three log files named run.log.<X>, where <X> is the test set number.
- run_processes.bat executes a partial test with parallel processes. It is difficult (if possible at all) to wait for completion of several processes using Windows shell command, therefore I ran each iteration manually. This batch file requires to specify four parameters and it calls to run_threads_impl.bat. It produces many small files named test.<T>.<N>.<P>.log, where <T> is the test number, <N> is the count of parallel processes, and <P> is the process number. The batch file parameters are:
run_processes.bat <T> <N> <I>
where <I> is count of iterations for each parallel process, <T> and <N> already described.
Also it contains four sub-folders with the results:
- threads1cpu_results - contains the results of the parallel thread tests on a single-processor computer.
- threads2cpu_results - contains the results of the parallel thread tests on a multiprocessor computer.
- processes1cpu_results - contains the results of the parallel process tests on a single-processor computer.
- processes2cpu_results - contains the results of the parallel process tests on a multiprocessor computer.
Appendix C: References
- Windows 2000 Performance Guide by Mark Friedman, Odysseas Pentakalos, 2002
This book has an excellent chapter on multiprocessing (chapter 5, to be exact). This book actually led me to the solution of the problem I had. The section 4 of this article is built mostly on this book's material.
- Server Performance and Scalability Killers by George V. Reilly, 1999
This article speaks about almost the same issue, and formulates several simple rules of writing scalable server applications.
- Application Design and Multiprocessor Performance from Windows 2000 Server Resource Kit
(I did not find it in online MSDN but it must be on your MSDN or Windows 2000 Server CDs.) This article suggests common guidelines of writing multithreaded applications for multiprocessor systems.
- Heap: Pleasures and Pains by Murali R. Krishnan, 1999
This article explains potential performance problems of the Windows heap and suggests interesting solutions.
- Optimization: Your Worst Enemy by Joseph M. Newcomer, 2000
An excellent article on performance optimization. It is not related to this article but I would recommend reading it anyway.
- Modern C++ Design: Generic Programming and Design Patterns Applied by Andrei Alexandrescu, 2002
This book has a very good chapter about writing a custom memory manager for small objects.
- ACE framework
This is an open-source multiplatform C++ library for development of real-time and network applications. It provides a set of classes for custom memory management.
- Programs Optimization Technique: Effective Using of Memory by Kris Kaspersky, 2003
An excellent book on performance optimization. It does not cover multiprocessor systems but it explains the architecture and performance issues of modern Intel processors and memory chips. Unfortunately, to the moment, this book is published in Russian only, so you will not find it on Amazon (let me know if you do).
- Effective STL by Scott Meyers, 2001
This book covers interesting aspects of custom memory allocators in STL and provides useful references. Look at the items 10 and 11.
- Windows Base Service > Memory section in MSDN
In this section, you will find information on dynamic heap functions and new low-fragmentation heap introduced in Windows XP/2003.
- Distributed Application Programming in C++ by Randall A. Maddox, 2000
This book discusses very basic things but it has a couple of paragraphs popularly describing the difference between multithreading and multiprocessing (at the end of chapter 11).


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 The correct algorithm would combine both techniques, and it is described in many books, but it is boring to implement it each time you need a buffer.
The correct algorithm would combine both techniques, and it is described in many books, but it is boring to implement it each time you need a buffer.