Introduction
I love the .NET Framework, C# and IntelliSense, but a lot of
people are still saying it's slower than C++, pointing out that video games and
"major applications" are still written in C++. Naysayers often point
out that apps like Office, Internet Explorer, and Windows Media Player are
still written in C++, apparently implying that C++ is still the best choice for
performance. But wait, isn't this just because those applications are older
than the .NET Framework itself, or because the .NET Framework has lousy support
for DirectShow, or less-than-ideal support for Direct3D?<o:p>
Well, I've been using C# for years and rarely had any complaint
about its performance--that is, until I wrote a program for a Pocket PC and was
shocked to discover that it required 35 seconds to start up.<o:p>
With this article, I am attempting to make a fair comparison
between the performance of C# and C++ (unmanaged), in both desktop and mobile (Windows CE) scenarios. So that the comparison is fair, I wrote most of the code in C# first, and manually ported it, line-by-line, to C++, replacing standard .NET classes with STL equivalents. Because this is labor-intensive, however, the variety and scope of the benchmarks are limited.
To compile both languages I used Visual Studio 2008; I have access to Visual Studio 2010, but Microsoft dropped support for Windows CE in VS 2010 so it was easier to keep using 2008. I welcome
readers to try compiling the C++ code on GCC (there is a small amount of Windows-specific code you may have to deal with) <o:p>or VS 2010 to see if it performs differently. Of course, any differences you observe may be caused by using a different processor as well as a different compiler. Likewise, if someone has access to Windows Phone 7, I welcome you to run the C# benchmark there and see if you get better results than I did for Windows CE.
My test workstation is a Quad-core 64-bit Intel Q9500 @ 2.83 GHz (but all tests are single-threaded) on Windows 7. The mobile device is a Mentor Ranger 4 with a 600MHz ARM processor, and .NET Compact Framework 3.5.
My main goal is to measure the performance difference in the
compiler/JIT and parts of the standard library that are used most often. I'm
largely limiting my tests to the C++ standard library anyway, so there's no way
we can compare the speed of things like XML parsing or JPG loading, which the
.NET Framework BCL can do but the C++ standard libraries cannot. No, my
benchmarks will be limited to the following areas:
- String handling:
std::string vs System.String - Hashtables:
hash_map<K,V> vs Dictionary<K,V> - Simple structures: in my work I often end up creating small performance-critical structures, such as a fixed-point type with a single integer field.
- Mathematical generics: You have to go to quite some effort to write math code using .NET Generics. Do you also suffer a performance hit?
- Simple arithmetic: add and subtract; multiply, divide and modulo by a constant, for different data types. I also try an integer square root algorithm (and its floating-point equivalent, for completeness).
- 64-bit integers: some compilers deal with these pretty poorly.
- Text file scanning: how fast can we read text files line by line?
- Sorting
- P/Invoke and no-op methods (C# only)
Before I start, I should mention that there's no easy way to match up garbage collections with benchmarks, so I do a GC before every C# benchmark and I do not attempt to include that GC time in the totals. However, it shouldn't matter much because most of these benchmarks do not allocate a large number of heap objects (except the string dictionary tests).
I'll get to the "real" benchmarking in a minute. But first...
<o:p>
Debug versus Release builds
Some C++ developers end up distributing Debug builds so that
"assert" statements continue to work, or so that they can debug the
production machine if they have to. Unfortunately, this tends to kill
performance, as the graph below shows.<o:p>
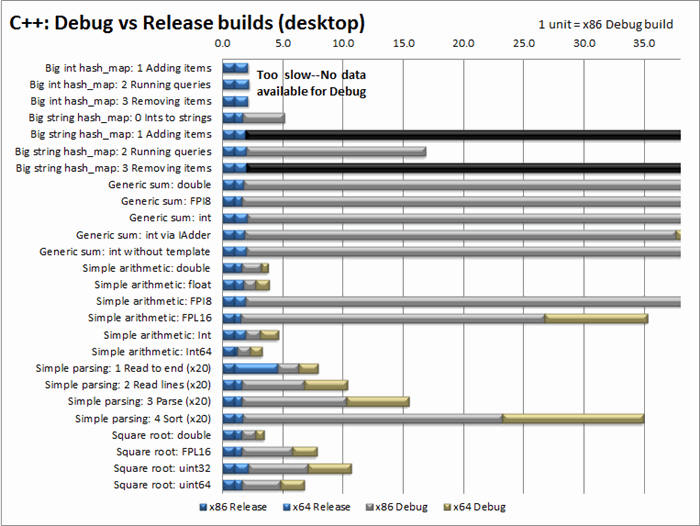
In this graph, the scale has been adjusted so that the x86
Release build takes one unit of time. Some operations, most notably function
calls and anything involving STL, are dramatically slower in desktop Debug
builds. I suspect "Generic sum" is so much slower mainly because the
STL vector it scans is slower; and you may find that hash_map is virtually
unusable in a debug build.<o:p>
When I first ran the x86 Debug benchmark, I noticed that it
seemed to be "hung". I stopped it in the debugger and found it was
running the "string hash_map: 1 Adding items" test. This test fills
the hashtable with 2.5 million items, clears the list, and fills it again three
more times. Well, when inserting the first item after a clear() command,
hash_map gets stuck doing who-knows-what for around 4 minutes, for a total
runtime of 16 minutes and 20 seconds (78 times longer than the Release build).
I left it running overnight, and discovered that the removal test is even
worse. This test tries to remove 10 million items, but the list size is limited
to 2.5 million so most of those requests fail. For whatever reason, this test
took 10 hours and 37 minutes, which is 9400 times longer than the Release
build! Understandably, I decided to stop the benchmark and disable the hash_map
tests in debug builds.
<o:p>
This graph also shows that the same piece of code can run at
many different speeds depending on your platform and compiler settings. For
example, some tasks, especially those involving 64-bit integers (or to a lesser
extent, floating point), run faster when targeting x64. Once in awhile, x64
handles a task more slowly (for some reason, reading a file with ifstream::read()
is much slower in 64-bit).
<o:p>
The C# results are more consistent:

In fact, only a few operations are significantly slower in a
C# Debug build compared to a Release build. One reason for this is that the
.NET standard library, known as the BCL (Base Class Library), is optimized even
when you are running a Debug build. This explains why the speed of the
Dictionary<K,V>, file and string parsing tests (which mainly stress the
BCL) are almost the same in Debug and Release builds. Additional optimizations seem
to be enabled when C# Debug builds run outside the debugger, as these
benchmarks did. In fact, the C# x86 Debug build outperforms the C++ x86 Debug
build in all tests except two.<o:p>
But of course, what we really care about is Release builds.
The rest of this article will examine Release builds only (using Visual
Studio's default compiler settings).
C++ vs C#: Hash tables
This test pits two types of .NET Dictionary against the
equivalent Microsoft C++ hash_maps. First I tried an <int, int>
dictionary, then a <string, string> dictionary in which each string is
merely the same set of integers converted to strings. You may be surprised:
C# wins this one by a landslide! The first test,
for example, runs 16 times faster in C# (x64). Why is the difference so large?
I'd love to leave you in suspense for awhile, but I just can't help blurting it
out: Microsoft's hash_map is simply terrible! I don't know how it's
implemented; I've looked at the code and I can hardly comprehend it. But I can
say with certainty that it's not the compiler's fault. I know this because I
wrote my own version of hash_map for my company, and my implementation runs
roughly ten times faster. I knew I got better performance from my hashtable,
but I didn't realize how dramatic the difference was until I saw the numbers.
Here are the results based on my implementation:
As you can see, C++ is much more competitive now. It wins some races, and loses others. My
hash_map is heavily inspired by the design of .NET's Dictionary, and I am
unable to guess why my version outperformed C# sometimes but was slower at
other times. Notably, C++ "int" queries are more than twice as fast
as C# queries, even while "int" inserts are sightly slower.<o:p>
The string tests use the same keys as the integer tests, but
converted to strings. The test marked "0" simply measures the time it
takes to convert (and discard) 10 million integers to 10 million strings. This
work is repeated in test "1", so you may want to mentally subtract
test "0" from test "1".
<o:p>
When it comes to strings, it is worth noticing first of all
that they are dramatically slower than integers, regardless of the programming
language you use, and for longtime programmers this will come as no surprise. I
believe C++ is at a fundamental disadvantage whenever strings are stored in
collections. The reason is that C# uses immutable strings, and no work is
required to construct or destruct a "copy" of a string. The C++ STL,
however, uses mutable strings, which require extra work to copy a
string--depending on how std::string is designed, either bookkeeping is
required to track how many std::strings point to the same string (this approach
makes modifying a string more expensive), or the entire string must be copied
(so changing a string is cheaper, but copying is more expensive). In any case,
when adding a string like "12345" to the hashtable, some work must be
done to make a copy.
<o:p>
On the other hand, the STL does have a slight performance
advantage, in that its template classes are specialized and optimized for every
specific data type at compile-time. Thus, the compiler can specifically
optimize hash_map<string,string> for strings. In contrast, the .NET
Framework specializes generics at run-time if they are based on value types
(such as Dictionary<int,int>) but not if they are based on reference
types (such as Dictionary<string,string>). Thus, there is a slight
overhead when the .NET hashtable calls string.GetHashCode and string.Equals. In
general I believe the C# design is a better balance, since it avoids code bloat--some
types of Dictionaries can share the same machine language code--while still
offering higher performance for simple types like "int" and
user-defined structures.
<o:p>
Unfortunately, the Compact Framework does not do as well:
<o:p>
In the integer case, the hashtable queries and removals are
over 3 times faster in C++, although insertion is still mysteriously slower.
The string tests are where things get bad, and somehow I am not surprised. The
.NETCF program I mentioned at the start, the one that needed 35 seconds to
start, was busy parsing strings and adding them to a list. String test 1 runs
3.5x slower in C#; test 2 is 9.1x slower; and test 3 is 7 times slower.<o:p>
Disclaimer: the above tests use sequential integer keys.
Therefore the hashtables enjoy virtually no collisions, which means that these
test results are probably better than real-world results.
<o:p>
C++ vs C#: Arithmetic
C++ is still widely used for numerical applications--apps in
which most of the time is spent in the application code, not the standard
library or waiting on I/O--because its compilers are considered very good at
optimization. For this benchmark I ran three numerical tests: a generic sum
(testing the speed of numeric templates/generics in a tight loop), a simple
arithmetic expression (multiplying/dividing by a constant, adding, and
subtracting), and an integer square root algorithm (plus its standard
floating-point version, for reference.)<o:p>
In addition to int, int64, float and double, I also tested
FPI8 and FPL16, fixed-point data types that I created myself. Many, if not
most, mobile devices have poor floating-point support, so I often use
fixed-point instead of floating-point on such devices. A fixed-point type in
C++ or C# is simply a struct with an integer inside it (FPI8 contains an int,
FPL16 contains a 64-bit int). Some of the low bits are treated as fractional.
The "8" in FPI8 means there are 8 fraction bits, so FPI8 can store
numbers between -16777216 and 16777215.996, with a resolution of about 0.004.
The fact that a "struct" is involved is an important part of the
benchmark: historically, compilers could not handle a structure that contains a
single value as well as that value by itself (outside the structure), but these
days most compilers do a good job.
<o:p>
The generic sum test in C# is based on an enhanced version
of a library written in 2004 by Rüdiger Klaehn, which observes that with some
extra developer effort, it is possible (although not especially easy) to write
and use C# generics to write fast math code that supports arbitrary number
types. I tested the following generic C# sum method:
public static T GenericSum<T, Math>(List<T> list, Math M) where Math : IMath<T>
{
T sum = M.Zero;
for (int i = 0; i < list.Count; i++)
sum = M.Add(sum, list[i]);
return sum;
} Of course, in C++ this would be simpler; the loop body would simply read "sum += list[i]". However, many C++ template libraries (Boost::GIL comes to mind) rely heavily on the compiler to inline tiny functions and eliminate empty structures, so I directly ported the convoluted C# code to C++ with the confidence that the compiler would make it fast:
template<typename T, typename Math>
T GenericSum(const vector<T>& list, Math& M)
{
T sum = M.Zero();
for(int i = 0; i < (int)list.size(); i++)
sum = M.Add(sum, list[i]);
return sum;
} For reference, I also included a non-generic integer-summing method in both languages. Note that because adding a number is such simple work, I did 10x as many iterations for this test as for the others.
Here are the results:
<o:p>
One of the C# sum tests, "int via IMath", sums up
the numbers through an interface instead of a "Math structure", and
there is a performance penalty for doing this because it involves a call
through an interface. It turns out that in C# it's easier to write and (more importantly) consume
generic math code through an IMath interface (explaining why is outside the
scope of this article), but as you can see there is a performance penalty for
doing so. Since I wrote the C++ sum function in the same
contorted way as the C#, I could perform a similar test involving a
pure virtual method, the closest thing C++ has to an interface. C# interfaces
seem more powerful than pure virtual methods, so you shouldn't blame C# too
much for losing the "int via IMath" test.
<o:p>
The "Simple arithmetic" test, admittedly, may have been a little too simple; two compilers of generally similar quality may optimize small pieces of code differently, so in hindsight it would have been better to test with a bigger piece of code to "average out" any differences. Anyway, this is what I did for each numeric type:
double total = 0;
for (int i = 0; i < Iterations; i++)
total = total - total / 4.0 + (double)i % 100000 * 3.0;
Part of this test is to see whether the compilers can optimize multiplication and modulus by a constant. The results show that C# did a better job in the "double" test, but a worse job in the FPL8 and FPL16 tests. Notably, .NET didn't handle FPI8 as well as a plain int, while the C++ results didn't change a lot between FPI8 and int.
The integer square root tests use the following algorithm:
public static uint Sqrt(uint value)
{
if (value == 0)
return 0;
uint g = 0;
int bshft = Log2Floor(value) >> 1;
uint b = 1u << bshft;
do {
uint temp = (g + g + b) << bshft;
if (value >= temp)
{
g += b;
value -= temp;
}
b >>= 1;
} while (bshft-- > 0);
return g;
}Sometimes, the instruction set (x86 vs x64) makes a bigger difference than the programming language. In particular, the x64 .NET JIT does much worse on the generics test than the x86 one. But even looking at x86 alone, it looks like C++ has an edge over C# in most of these tests, although the differences are not that large.
Unfortunately for me, the Compact Framework performs dramatically worse in the arithmetic tests:
For this graph I added ratio-bars to the right side, so you can see just how badly the CF is doing (I would have liked to add ratio-bars to the previous graph too, but I had to spend a lot of time working around charting bugs in Excel, and it's not something I care to do again.)
In fact, C++ beats the Compact Framework by a huge margin on
most of these tests. The "best" results (where .NETCF is only
slightly slower) involve the double floating point type, but this is only
because most of the time is spent in the system floating-point emulation
library, regardless of your programming language. This is a huge
disappointment; it suggests that the Compact Framework is incapable of doing
math or algorithms quickly, and the results are even worse when using FPI8 or FPL16. Plus, it
might not optimize generics very well; notice that the C# "int
(non-generic)" test is faster than the "int" (generic) test.<o:p>
Notice that "Square root: FPL16" is slower than
uint64 (ulong), in both C++ and C#. The reason for this is not that ulong is wrapped in a FPL16 structure. Rather, the reason
is that FPL16 has 16 fraction bits and uint64 has none, so the square root
algorithm (which operates on a raw uint64) requires more iterations to compute
the square root.
File reading, parsing and sorting
In this test I try out two different ways of reading a 400KB
text file with about 17000 lines: either by reading the entire file at once
into a buffer, or by reading it line-by-line. The file has been loaded before
so that it is in the disk cache. This benchmark does not measure disk
performance, nor do I want it to.<o:p>
In C++ I used a std::ifstream, and in C#, I used
System.IO.File wrapped in a StreamReader. The text file contained
"dictionary entries": key-value pairs separated by ":=".
The value can span multiple lines; if a line does not contain := then it is assumed to be a continuation of the value on the previous line. The
dictionary entries are collected into a C# List or C++ vector, then randomized
a bit (to ensure sorting requires some work) and sorted by key in a case-insensitive manner. Here are the
results on my PC:
<o:p>
The "x20" indicates that the file is scanned 20
times, just to eat up time on the clock.<o:p>
Like any clever C++ coder, I optimized parts 2 and 3 by
adding empty strings to the end of the vector, and then creating the strings
in-place so that it is not necessary to copy them into the vector. Even so, C#
is quite competitive in these tests. The winner of the "Parse" test (which involves calling IndexOf, Substring and the C++ equivalents in std::string) depends on the platform (x86 or x64). The one place where C++ definitely wins is
during the case-insensitive string sort (std::sort vs List.Sort). I wonder whether the C#'s ability to
sort Unicode (É < õ), which _stricmp presumably cannot do, has something
to do with this result.
<o:p>
C++ ifstream does a terrible job, however, at reading lines
from the file. C# actually has to do more work in tests 1 and 2, because it is
decoding UTF-8 to UTF-16. Standard C++, in contrast, doesn't support conversion
between text encodings, and these tests use "char" strings (not
wchar_t); the only extra work C++ has to do is to convert line endings (\r\n to
\n), but C# does this work too. Why, then, does C++ take about four times as
long? I can only assume that Microsoft botched their ifstream implementation,
just like their hash_map. Even the Compact Framework can read a file faster
than ifstream:
<o:p>
But again, compared to C++, the parse test takes 8 times
longer in the Compact Framework, and the sorting test takes a whopping 15 times
longer. It would have been nice to look at the disassembly to see why it's so slow, but the debugger reports that disassembly is not supported in the Compact Framework.<o:p>
P/Invoke
After seeing the dismal results of the Compact Framework
tests, the question came up: what if some of the code were written in C++ and
called from C#? This could compensate for some of the slowness of the Compact
Framework. If you use P/Invoke a lot, though, it’s important to consider how
long it takes to cross the boundary between C# and C++.
<o:p>
I tested P/Invoke performance by calling a very simple DLL
that I made myself. The functions in that DLL do something trivially simple,
such as adding two numbers or returning the first character of a string. Below
you can see both .NET desktop and Compact frameworks here, and when I added this
test, I also added Mono as a test platform (I don’t have time to redo all the
other graphs to include Mono, though).<o:p>
As my tests show, crossing that boundary isn’t what I’d call
cheap, even if the arguments and return values are simple integers.
<o:p>
On my workstation, you can call Add(int,int) about 25
million times per second in the x86 and x64 versions of .NET (112 cycles per
call at 2.83 GHz). Mono is more than twice as fast (45 cycles), and the Compact
Framework manages 2.74 million calls per second (219 cycles per call at 600 MHz). Now,
these results are not terrible. But
non-P/Invoke calls are much faster, as you’ll see below.<o:p>
Passing strings or structures makes P/Invoke calls much
slower in some cases (but not all cases). If the C++ method returns a string
then .NET must convert it to a System.String,
which of course takes extra time. If the C++ string has type char*, then additionally a type
conversion occurs; but since .NET does not support UTF-8 conversion, this
conversion is probably a simple truncation from 2 bytes to 1 byte (or expanding
1 bytes to 2 bytes on return). However, you can pass strings to C++ very fast
using wchar_t*, since the string is not copied. (Note: if the C++
function modifies the string, be sure to use StringBuilder instead of string,
or the immutable string will be modified, which is illegal and dangerous.)<o:p>
I tested how well P/Invoke handles structures by marshaling
between .NET’s System.Drawing.Point
structure and Win32’s POINT
structure. MakePoint() takes two
integers and returns a Point, while GetPointY is passed a Point and returns its Y coordinate. The
interesting thing about these two methods is that the x86 marshaller handles
them very slowly, but all other CLR versions are fast. The MakePointIndirect() function returns a pointer to a Point (a static
variable inside the function), which the C# caller must unpack using Marshal.PtrToStructure.
You can see that this is very slow, too. If you want to make sure that a
structure is passed or returned to C++ code quickly, be sure to pass it by
reference, which the GetPointYIndirect()
function does, and do not return a structure by value.<o:p>
The .NET Compact Framework has some marshaling limitations:
- Passing or returning floating point values is not allowed (if I’m not mistaken, this limitation makes no sense, because floating point values are passed no differently than integer values on ARM.)
- Passing or returning ANSI (1-byte-per-char) strings is not allowed.
- Passing or returning structures is not allowed.
If you have to pass floating point values or structures, you must pass them by reference, not by value. That’s why I made an extra test for adding a pair of double*. Since there is an extra cost for converting a returned double* to a double, you’re better off using an "out double" parameter instead of an IntPtr (i.e. double*) return value; the same guideline applies to structures.
So, how much faster are normal, non-P/Invoke calls? Look how fast do-nothing NoOp() functions can be called:
You can see here that 10 million non-inlined calls take
around 24 milliseconds on the desktop, as compared to about 400 milliseconds
for NextInt(), a trivial C function that increments and returns a counter, or
160 milliseconds if NextInt() is called from Mono. Thus, simple P/Invoke calls are about 16
times slower than non-inlined method calls in .NET (and 18-23 times slower than
virtual method calls), about 6 times slower in Mono, and 9 times slower in the
Compact Framework (380 ms vs 42 ms).<o:p>
This means that you can never "optimize" .NET code by using
P/Invoke to call a function that does very little work. For example, if the
C++ version of your code is twice as fast as the C# version, and P/Invoke uses
about 110 clock cycles minimum (210 in CF), each C++ function call will have
to do (on average) 110 (or 210) clock cycles of work just to “break even”
with your C# speed.<o:p>
And what about inlining? If a method does very little work,
these results show that it will be much faster still if it is inlined. The
“static no-op” test allows inlining of a static function that does nothing at
all, which means that the test effectively just measures an empty for-loop.
Clearly, one iteration of the for-loop is much faster than a non-inlined method
call (except in the Compact Framework).<o:p>
Actually, the inlined x64 version seems almost impossibly
fast, at 0.001 seconds for 10 million calls. Just to be sure, I temporarily did
100 times as many loop iterations, and found that .NET x64 does one billion
iterations in 89.5 milliseconds, or 11.2 billion iterations per second, which
is 4 iterations per clock cycle. Maybe the x64 JIT does some fancy loop
unrolling, but the debugger wouldn’t let me see the assembly for some reason.<o:p>
In this "trivial method calls" test I actually started by
testing an Add(i, i) method (where i is the loop counter), but it turns out
that the difference between Add() and a no-op is very small (2-3 ms on the
desktop). In other words, the call itself is much slower than passing "int"
arguments or adding the arguments together. So I got rid of the arguments, so
that you can see the basic call overhead by itself, with nothing but a for-loop
getting in the way.<o:p>
The "no-inline" test uses the [MethodImplAttribute(MethodImplOptions.NoInlining)]
attribute to ensure that a static no-op method is not inlined. Strangely, the
method that uses this attribute (which is non-virtual) is consistently slower
than a "virtual" no-op method in all desktop CLRs.
Only the Compact Framework agrees with the widely-believed
notion that virtual functions are slower, and wow, virtual functions are really
very slow on that platform! The results seem to suggest that the Compact
Framework uses the same mechanism for virtual dispatch and interface dispatch,
which is sad because its interface dispatch is clearly quite slow (9 million
calls per second, or 66.6 cycles per call, compared with 25.2 cycles for a
non-virtual no-op).<o:p>
Relative performance between CLRs
I made one more graph that you might find interesting. It’s
the relative performance of different implementations of the CLR. All the
benchmarks are scaled so that .NET x86 uses 1 unit of time (I must scale the
results somehow in order to present all the tests on the same graph.)<o:p>
I am happy to report that all benchmarks ran
without modification under Mono. The Mono results are only shown for x86
because the download Mono page does not offer an x64 version for Windows (or an
ARM version for WinCE.)
Of course, the Compact Framework is not directly comparable
as it runs on a different processor, but I included it for completeness, with
10% of the workload (I estimate from a lot of benchmarking experience that the
processor itself is, at best, 1/7 as fast as my workstation for single-threaded
code, or slower when running complex or memory-intensive code.)<o:p>
As I mentioned before, some of the P/Invoke tests are very
slow under the x86 CLR, so the time measurements for the other platforms are
tiny in comparison. x64 outperforms x86 in other areas too, such as "long" arithmetic and string handling, but for some reason the "Generic sum" tests are
slower under x64 and Mono, and floating-point handling seems a little slower
too.<o:p>
Mono does okay in general, and does P/Invoke especially
well, but it falls behind Microsoft’s x86 CLR in most other tests. The
case-insensitive sort, FPI8 arithmetic, long arithmetic and Generic Sum tests
run fairly slowly under Mono, but the hashtable (Dictionary) and Square root
tests gave decent results.<o:p>
The Compact Framework, of course, gave a lot of poor
results. Even ignoring the floating-point tests (which use software emulation),
three tests went right off the right side of the graph. For example, the Sort
test took 13.0 times longer than x86, but since the mobile benchmark performs
10% as many sorts, this really means that a C# string Sort would takes 130
times longer on the mobile device than the same C# on my workstation. In fact, I
suspect it was a string sorting operation that was the main cause for the
35-second startup time I mentioned at the beginning of this article. Only the
P/Invoke tests, and the conversion of "Ints to strings", were relatively quick
in the Compact Framework.
Conclusion
The results seem conclusive: if you're developing software
for the desktop, and (like me) you are equally skilled in C# and C++, it's safe
to take advantage of the simpler syntax, rich standard libraries, stellar
IntelliSense and reduced development effort that C# offers. In general there is only a small performance penalty for C# versus C++ with STL, and certain "bad" parts of the Microsoft STL, like hash_map, are dramatically slower than the equivalent C#.
Of course, C# coders tend to program in different ways than C++ coders: they use LINQ-to-objects (which can be very slow if used carelessly), they may not tune their algorithms, they may use high-overhead libraries like WPF, prefer XML files to plain text files, use reflection heavily, and so on. These differences may lead to slower programs, but I believe a performance-conscious C# programmer can write programs that are almost as fast and memory efficient as their C++ counterparts.
If you use Mono
there will be an extra speed penalty, but it’s not too bad.<o:p>
However, if you happen to be developing for Windows CE, the
choice is unclear. The Compact Framework can do some tasks well enough (such as reading from a file), but
string processing, ordinary loops and arithmetic, structure manipulation and
other basic tasks seem to be completely unoptimized. C# would still be
acceptable if you won't be doing any complex algorithms or heavy string
manipulation. Probably a hybrid solution, where Compact Framework code calls
performance-critical C++ over P/Invoke, should be used to overcome its abysmal
performance. Mono built for ARM might also offer an improvement, but there is
no version currently available for Windows CE.<o:p>
History
June 17, 2011: Initial version





