
Tree Iterators
Discussing about Tree Iterators: Choices of Datastructure and Algorithm
Introduction
Maybe you have already remarked that a tree is a two-dimensional data structure that can't be accessed linearly, like you should do with a list. To traverse a tree, you have to visit all its nodes, with respect to their orders and hierarchy. This can be done by using recursivity or loops.
An object-oriented approach of tree traversal is to build a most generic as possible class that encapsulate the traversal algorithm. A modern and good way to do that is building a tree iterator.
This article talks about tree iterators and different choices that can be taken while coding them for taking account performance, reusability and comprehension.
Background
First, we assume that you are familiar with tree data structures. In this case, you know that a tree is a hierarchical structure, organized in linked nodes. It can also be considered as a particular case of graphs (an acyclic connected graph). Each node has a unique parent and zero or several children. Nodes at the bottommost level of the tree are called leaf nodes.
Iterators and C#
An iterator is an object that can iterate through a container data structure, and display, stay by step in incremental manner, its elements. In object-oriented programming, the Iterator pattern is a design pattern that encapsulates the internal structure of the iteration process.
Widely used in the C++ STL, it is implemented there as a pointer that can be increased with the ++ operator. This can also be done with C#, but the Framework provides for us another and convenient approach: the foreach keyword. In this case, the Iterator must implement the IEnumerator interface.
// Define the data container : a list of strings
StringList mylist = new StringList();
// C++ STL syntax :
ListIterator iterator = new ListIterator(mylist);
while(iterator++) ShowValue(iterator.Value);
// C# enumerator syntax :
foreach(string value in mylist) ShowValue(value);
As you can see, the C++ syntax is very natural. You first define the iterator, and then use it in a while loop.
But, what about the C# syntax ? Mmmh, it's not straightforward, but let's see the basic mechanism. In fact, the class StringList implements the IEnumerable interface and provides a method called GetEnumerator() that returns an iterator on the list. Thus, before enumerating, the IEnumerable instance calls the GetEnumerator() method that provides the iterator and increments it in each loop.
In the Visual Studio 2005 version, Microsoft came with a very useful new keyword: yield. If you don't know this magic keyword, I suggest you go urgently and read this article. Otherwise, you might know that it can save much time, avoiding you the need to create the IEnumerator class. In this case, the compiler will generate it for you. Read this excellent article on the yield keyword.
The Choice of the Tree Structure
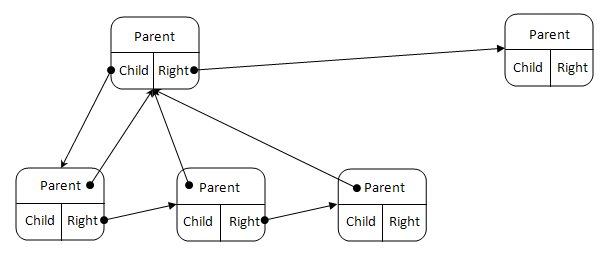
Trees can be represented in many ways. Because trees are organized sets of nodes, it is natural to consider nodes as a basis. A node can have zero, one or more children. The first idea is to set a list of nodes to a node. This is not the chosen approach in this article, because the list implementation is not optimized in the case of nodes with a few children (binary trees, for example). For a more generic and flexible implementation, I prefer a linked list, like the one drawn in the picture below:
public interface INode<T>
{
INode<T> Parent { get; set; }
INode<T> Child { get; set; }
INode<T> Right { get; set; }
}
As you can see, each node has a parent, a right neighbour, and a child. You can remark too:
- If the parent is
null, the node is the root of the tree. - If the right is
null, the node is the rightmost of its parent's children. - If the child is
null, the node is a leaf (the bottommost of the branch).
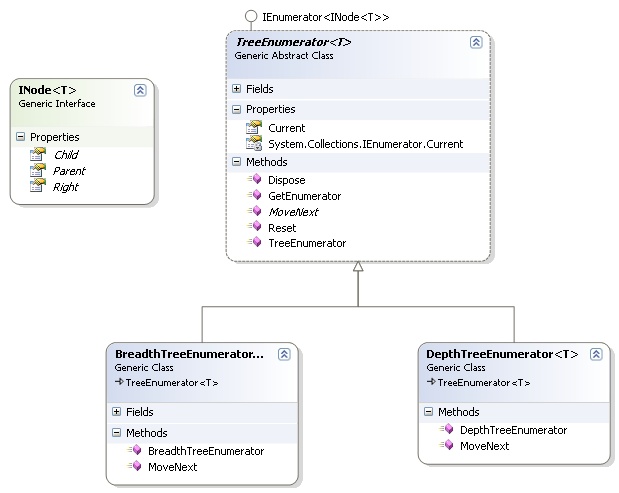
The code defining the generic process of iteration is easy and straightforward to write. Note that because it's generic, this algorithm does really nothing and must be implemented in an inherited class. This is why the following class is declared as abstract:
public abstract class TreeEnumerator<T> : IEnumerator<INode<T>>
{
// Contains the original parent tree.
protected INode<T> _Tree = null;
// Contains the current node.
protected INode<T> _Current = null;
// Constructor.
// The parameter tree is the main tree.
public TreeEnumerator(INode<T> tree) {
_Tree = tree;
}
// Get the explicit current node.
public INode<T> Current { get { return _Current; } }
// Get the implicit current node.
object System.Collections.IEnumerator.Current {
get { return _Current; }
}
// Increment the iterator and moves the current node to the next one
public abstract bool MoveNext();
// Dispose the object.
public void Dispose() {
}
// Reset the iterator.
public void Reset() {
_Current = null;
}
// Get the underlying enumerator.
public virtual TreeEnumerator<T> GetEnumerator() {
return this;
}
}
Tree Traversal Algorithms and Their Implementation
There are two families of tree traversal: the in-depth and the in-breadth algorithms. The first algorithm can be easily written using recursivity, whereas the latter needs a FIFO structure for memorizing already visited nodes. See more information on tree traversal.
For iterator purpose, it was not conceivable to use recursive methods. The traditional while loops have been preferred. I expose here only the depth traversal algorithms. The breadth algorithm can be downloaded in the files section (with the entire Visual Studio Solution).
public class DepthTreeEnumerator<t> : TreeEnumerator<t>
{
public DepthTreeEnumerator(INode<t> tree)
: base(tree) { }
public override bool MoveNext() {
if (_Current == null) _Current = _Tree;
else if (_Current.Child != null) _Current = _Current.Child;
else if (_Current.Right != null) _Current = _Current.Right;
else {
// The current node has no more child node
INode
Performance Comparison
Here is the code I used to compare the classic implementation with the yield method implementation.
class Program
{
// The entry point of the program.
static void Main(string[] args) {
// Build the node.
Node tree = new Node(1);
tree.Child = new Node(2);
tree.Child.Right = new Node(5);
tree.Child.Child = new Node(3);
tree.Child.Child.Right = new Node(4);
tree.Child.Right.Child = new Node(6);
tree.Child.Right.Child.Right = new Node(7);
int imax = 100;
double[] ratios = new double[imax];
ulong iter = 10000;
for (int i = 0; i < imax; i++)
ratios[i] = TestPerformance(tree, iter);
StringBuilder sb = new StringBuilder();
foreach(double value in ratios)
sb.Append(value.ToString()+";");
string copy = sb.ToString();
}
// Define a yield return method iteration.
public static IEnumerable<Node> MoveNext(Node root) {
yield return root;
if (root.Child != null)
foreach (Node node in MoveNext((Node)root.Child))
yield return node;
if (root.Right != null)
foreach (Node node in MoveNext((Node)root.Right))
yield return node;
}
public static double TestPerformance(Node tree, ulong iter) {
DateTime start;
// Classic method test
start = DateTime.Now;
for (ulong i = 0; i < iter; i++) {
DepthTreeEnumerator<int> enumerator;
enumerator = new DepthTreeEnumerator<int>(tree);
foreach (Node node in enumerator) {}
long ticks1 = ((TimeSpan)(DateTime.Now - start)).Ticks;
}
// Yield return method test
start = DateTime.Now;
for (ulong i = 0; i < iter; i++) {
foreach (Node node in MoveNext(tree)) { }
}
long ticks2 = ((TimeSpan)(DateTime.Now - start)).Ticks;
return (double)ticks2 / (double)ticks1;
}
}
The result is that the classic method is up to 5 times faster than the yield return method! So, it's clear that with the addition of simple tests, it can be shown that the yield keyword is not adapted in this kind of work.
Example Application
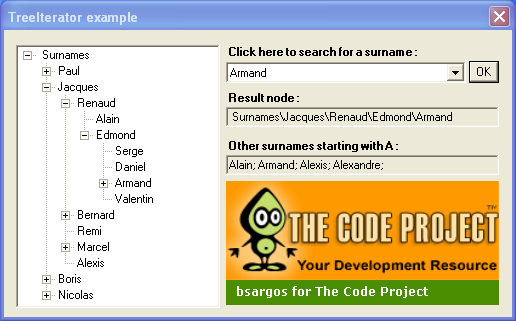
Theory discussions are not understandable without a concrete application. That's why I add to this article an example application of tree iterators, useful in the "true life" of a C# developer. This application exposes a TreeView with many nodes, each one displaying a French surname.
To test the application, download the file above, unzip it and build the solution. Run the TreeIterator.Example project (selected by default).
Then, in the dialog box that appears, select a surname among the ones suggested by the combo box. Click OK. Finally, three things happen at the same time:
- The node matching your selected surname is visible
- The first (and readonly)
TextBoxdisplays the path to the selected node - All the surnames starting with the first letter of the selected surname are listed in the bottomost
TextBox
The application runs fine. But to appreciate the application of the iterator, we need to examine the code. In this project, there are two main files:
- SurnameTreeNode.cs
- MainForm.cs
Well, how does it work ? It's not really difficult. Remember, we already have defined a tree iterator that does all the traversal for us. But this iterator has been thought of for working on any INode structure. So, to achieve the task, we need to create a new class (we'll name it SurnameNode) that derives from INode. This class will make the link between the TreeView nodes and the iterator. The only thing we have to do is define the properties of a SurnameNode object :
// Get or set the parent of the Node.
public INode<TreeNode> Parent {
get { return _Node == null ? null : new SurnameTreeNode(_Node.Parent); }
set { throw new NotImplementedException();
}
// Get or set the leftmost child of the Node.
public INode<TreeNode> Child
{
get {
if (_Node == null || _Node.Nodes == null) return null;
if(_Node.Nodes.Count <= 0) return null;
return new SurnameTreeNode(_Node.Nodes[0]);
}
set { throw new NotImplementedException(); }
}
}
// Get or set the right neighbour of the Node.
public INode<TreeNode> Right
{
get {
if (_Node == null || _Node.Parent == null) return null;
if(_Node.Parent.Nodes.Count <= _Node.Index + 1) return null;
var node = _Node.Parent.Nodes[_Node.Index + 1];
return new SurnameTreeNode(node );
}
set { throw new NotImplementedException(); }
}
Ok. Now, if we want to use our iterator in a foreach loop, we have to defer its traversal with a yield return loop :
// Returns an enumeration of the tree nodes, with a depth traversal.
private IEnumerable<TreeNode> Enumerate() {
// Instantiate the iterator
DepthTreeEnumerator<TreeNode> enumerator = null;
enumerator = new DepthTreeEnumerator<TreeNode>(
new SurnameTreeNode(this.treeView1.Nodes[0])
);
// Defer the traversal of the tree
foreach (SurnameTreeNode node in enumerator) yield return node.Node;
}
This method must be used like this:
IEnumerable
The last thing to do is writing search methods. That's where the power of iterators come in. We can now handle nodes linearly, like a list, and then apply LINQ method extensions. It's very easy!
The first use consists in getting all the surnames of the tree, ordered by surname. Here's the code to do so:
// Fill the combo box with all the surnames the tree contains.
IQueryable<string> items;
items = Enumerate().OrderBy(node=>node.Text).Select(node=>node.Text);
this.comboBox1.Items.AddRange(items.ToArray());
Then, we can search for a node matching a specified name :
string name = "Boris"
TreeNode resultnode = Enumerate().Single(node => node.Text == name);
Or we can find all the names that start with a specified letter :
string letter = "B"
var nodes = Enumerate().Where(node=>node.Text.StartsWith(letter)));
List<string> names = nodes.Select(node=>node.Text).ToList();
Points of Interest
In this article, we saw an simple, generic and efficient way to traverse trees, with two different algorithms. We also saw that implementing yield return based-algorithms gave bad performances. Then, we could apply our library on daily development problems, and prove that iterators, combined with LINQ, can become powerful when searching elements in non-ordered trees.
History
- 20th March, 2009: Initial post